PYTHON DECEMBER 2023
|
”’ |
|
|
|
|
var1 = 5
print(type(var1)) #<class ‘int’>
var1 = 5.0
print(type(var1)) #<class ‘float’>
var1 = “5.0”
print(type(var1)) #<class ‘str’>
var1 = “””5.0″””
print(type(var1)) #<class ‘str’>
var1 = True
print(type(var1)) #<class ‘bool’>
var1 = 5j
print(type(var1)) #<class ‘complex’>
length = 100
breadth = 15
area = length * breadth
peri = 2*(length + breadth)
print(“Area of a rectangle with length”,length,“and breadth”,breadth,“is”,area,“and perimeter is”,peri)
# f-string
print(f”Area of a rectangle with length {length} and breadth {breadth} is {area} and perimeter is {peri}“)
print(f”Area of a rectangle with length {length} and breadth {breadth} is {area} and perimeter is {peri}“)
# float value
tot_items= 77
tot_price = 367
price_item =tot_price/tot_items
print(f”Cost of each item when total price paid is {tot_price} for {tot_items} items is {price_item:.1f} currency”)
”’
Assignment submission process:
1. Create Google drive folder: share with the instructor
2. within this folder – add your .py files
”’
”’
Assignment 1:
1. Write a program to calculate area and circumference of a circle and display info in a formatted manner
2. WAP to calculate area and perimeter of a square
3. WAP to calculate simple interest to be paid when principle amount, rate of interest and time is given
4. WAP to take degree celcius as input and give Fahrenheit output
”’
name, country,position=“Virat”,“India”,“Opening”
print(f”Player {name:<10} plays for {country:>12} as a/an {position:^15} in the cricket.”)
name, country,position=“Mangwaba”,“Zimbabwe”,“Wicket-keeper”
print(f”Player {name:<10} plays for {country:>12} as a/an {position:^15} in the cricket.”)
# operators: arithematic operators
# -5 * -5 = 25
print(5j * 5j) # -25 +0j
val1, val2 = 10,3
print(val1 + val2)
print(val1 – val2)
print(val1 * val2)
print(val1 / val2) #3.333 – always be float
print(val1 % val2) # modulo (%) – remainder
print(val1 // val2) #integer division (non decimal)
print(val1 ** val2) # power() 10**3 = 10*10*10
# comparison operators
# complex numbers are square root negative numbers
# square root of 25 -> 5
# square root of -25? 25 * -1 = 5j
# asking, is …
# your output is always a bool value – True or False
val1,val2,val3 = 20,20,10
print(val1 > val2) #val1 greater than val2 ?
print(val1 >= val2)
print(val1 > val3) #val1 greater than val3 ?
print(val1 >= val3) # True
print(“Second set:”)
print(val1 < val2) #F
print(val1 <= val2) #T
print(val1 < val3) #F
print(val1 <= val3) #F
print(“third set:”)
print(val1 == val2) # T
print(val2==val3) # F
print(val1 != val2) # F
print(val2!=val3) # T
”’
a = 5 # assign value 5 to the variable a
a ==5 # is the value of a 5?
a!=5 # is value of a not equal to 5 ?
”’
## Logical operators: and or not
”’
Committment: I am going to cover Python and SQL in this course
Actual 1: I covered Python and SQL
Actual 2: I covered SQL
Actual 3: I covered Python
Committment 2: I am going to cover Python or SQL in this course
Actual 1: I covered Python and SQL
Actual 2: I covered SQL
Actual 3: I covered Python
”’
#logical operators takes bool values as input and also output is another bool
print(True and True ) # T
print(False and True ) #F
print(True and False ) #F
print(False and False ) #F
print(“OR:”)
print(True or True ) # T
print(False or True ) #T
print(True or False ) #T
print(False or False ) #F
print(“NOT”)
print(not True)
print(not False)
val1,val2,val3 = 20,20,10
print(val1 > val2 and val1 >= val2 or val1 > val3 and val1 >= val3 or val1 < val2 and val2!=val3)
# F and T or T and T or F and T
# F or T or F
# T
# Self Practice: output is True – solve it manually
print(val1 <= val2 or val1 < val3 and val1 <= val3 and val1 == val2 or val2==val3 or val1 != val2)
# Bitwise operator : & | >> <<
print(bin(50)) #bin() convert into binary numbers
# 50 = 0b 110010
print(int(0b110010)) #int() will convert into decimal number
print(oct(50)) # Octal number system: 0o62
print(hex(50)) #hexadecimal: 0x32
# Assignments (3 programs) – refer below

num1 = 50 # 0b 110010
num2 = 25 # 0b 011001
print(bin(50))
print(bin(25))
”’
110010
011001
111011 (|)
010000 (&)
”’
print(int(0b111011)) #bitwise | result = 59
print(int(0b10000)) #bitwise & result = 16
print(50&25)
print(50|25)
”’
Left Shift:
110010 << 1 = 1100100
Right Shift:
110010 >> 1 = 11001
”’
print(50<<2) # 50*2*2 : 110010 0 0
print(int(0b11001000))
print(50>>2) # 50 /2 /2
print(int(0b1100))
# input() – to read values from the user
a = input(‘Enter the value for length:’)
print(a)
print(type(a))
a = int(a)
print(type(a))
# int(), float(), str(), complex(), bool()
b = int(input(“Enter the value for breadth:”))
area = a*b
print(“Area of the rectangle is”,area)
if total_marks>=200:
print(“Congratulations! You have passed the exam”)
print(“You have 7 days to reserve your admission”)
else:
print(“Sorry, You have not cleared the exam”)
print(“Try again after 3 months”)
print(“Thank you”)
#
marks = 75
”’
>=85: Grade A
>=75: B
>=60: C
>=50: D
<50: E
”’
if marks>=85:
print(“Grade A”)
elif marks>=75:
print(“Grade B”)
elif marks>=60:
print(“Grade C”)
elif marks>=50:
print(“Grade D”)
else:
print(“Grade E”)
print(“Done”)
###.
marks = 85
”’
>=85: Grade A
>=75: B
>=60: C
>=50: D
<50: E
”’
if marks>=85:
print(“Grade A”)
if marks>=75 and marks<85:
print(“Grade B”)
if marks>=60 and marks<75:
print(“Grade C”)
if marks>=50 and marks<60:
print(“Grade D”)
if marks<50:
print(“Grade E”)
print(“Done”)
### NEST IF
marks = 98.0001
”’
>=85: Grade A
>=75: B
>=60: C
>=50: D
<50: E
>90: award them with medal
”’
if marks>=85:
print(“Grade A”)
if marks >= 90:
print(“You win the medal”)
if marks>98:
print(“Your photo will be on the wall of fame”)
elif marks>=75:
print(“Grade B”)
elif marks>=60:
print(“Grade C”)
elif marks>=50:
print(“Grade D”)
else:
print(“Grade E”)
print(“Done”)
Practice basic programs from here:
https://www.scribd.com/document/669472691/Flowchart-and-C-Programs
”’
# check if a number is odd or even
num1 = int(input(“Enter the number: “))
if num1<0:
print(“Its neither Odd or Even”)
else:
if num1%2==0:
print(“Its Even”)
else:
print(“Its Odd”)
## check the greater of the given two numbers:
num1, num2 = 20,20
if num1>num2:
print(f”{num1} is greater than {num2}“)
elif num2>num1:
print(f”{num2} is greater than {num1}“)
else:
print(“They are equal”)
## check the greater of the given three numbers:
num1, num2,num3 = 29,49,29
if num1>num2: # n1 > n2
if num1>num3:
print(f”{num1} is greater”)
else:
print(f”{num3} is greater”)
else: # n2 is greater or equal to
if num2 > num3:
print(f”{num2} is greater”)
else:
print(f”{num3} is greater”)
##
#enter 3 sides of a triangle and check if they are:
#equilateral, isoceles, scalene, right angled triangle
side1,side2,side3 = 90,60,30
if side1==side2:
if side1 == side3:
print(“Equilateral”)
else:
print(“Isoceles”)
else:
if side1==side3:
print(“Isoceles”)
else:
if side2==side3:
print(“Isoceles”)
else:
print(“Scalene”)
#modify the above code to handle Right Angled triangle logic
# FOR : know how many times you need to repeat
# WHILE : dont know how many times but you have the condition
# range(start, stop,step): starts with start, goes upto stop (not including)
# step: each time value is increasesd by step
# range(10,34,6): 10, 16, 22, 28
# range(start, stop) : default step is 1
# range(10,17): 10,11,12,13,14,15,16
# range(stop): default start is zero, default step is 1
# range(5): 0,1,2,3,4
# generate values from 1 to 10
for counter in range(1,11): # 1,2,3…10
print(counter,end=“, “)
print()
print(“Thank You”)
# generate first 10 odd numbers
for odd_num in range(1,11,2): # 1,2,3…10
print(odd_num,end=“, “)
print()
print(“———-“)
for counter in range(10):
print(2*counter+1,end=“, “)
print()
print(“———-“)
# generate even numbers till 50
for even_num in range(0,50,2): # 1,2,3…10
print(even_num,end=“, “)
print()
##############
# WHILE: is always followed by a condition and only if the condition is true, u get in
# WAP to print hello till user says so
user = “y”
while user==“y”:
print(“Hello”)
user = input(“Enter y to continue or anyother key to stop: “)
##
print(“method 2”)
while True:
user = input(“Enter y to continue or anyother key to stop: “)
if user!=“y”:
break
print(“Hello”)
print(“Thank you”)
count = int(input(“How many times you want to print: “))
while count >0:
print(“Hello”)
count-=1 #count = count-1
”’
* * * * *
* * * * *
* * * * *
* * * * *
* * * * *
”’
n=5
for j in range(n):
for i in range(n):
print(“*”,end=” “)
print()
”’
*
* *
* * *
* * * *
* * * * *
”’
n=5
num_stars=1
for j in range(n):
for i in range(num_stars):
print(“*”,end=” “)
print()
num_stars+=1
#
n=5
for j in range(n):
for i in range(j+1):
print(“*”,end=” “)
print()
”’
* * * * *
* * * *
* * *
* *
*
”’
for j in range(n):
for i in range(n-j):
print(“*”,end=” “)
print()
”’
* * * * *
* * * *
* * *
* *
*
”’
for j in range(n):
for k in range(j):
print(“”, end=” “)
for i in range(n-j):
print(“*”,end=” “)
print()
””
Practice Program:
*
* *
* * *
* * * *
* * * * *
”’
”’
Multiplication table:
1 * 1 = 1 2 * 1 = 2 … 10 * 1 = 10
1 * 2 = 2 2 * 2 = 4
…
10 * 10 = 100
”’
for mul in range(1,11):
for tab in range(1,11):
print(f”{tab:<2}* {mul:<2}= {tab*mul:<2}“,end=” “)
print()
”’
Print prime numbers between 5000 and 10,000
10 – prime or not
2
10%2==0 => not a prime
3
4
”’
for num in range(5000,10000):
isPrime = True
for i in range(2,num//2+1):
if num%i==0:
isPrime = False
break
if isPrime:
print(num,end=“, “)
”’
num = 11
isPrime =T
i in range(2,6)
isPrime =F
”’
”’
Before you use while loop, decide:
1. Should the loop run atleast once (Exit Controlled), or
2. Should we check the condition even before running the loop (Entry controlled)
”’
# method 1: Exit controlled
while True:
num1 = int(input(“Enter first number: “))
num2 = int(input(“Enter second number: “))
print(“Your Option: “)
print(“1. Add”)
print(“2. Subtract”)
print(“3. Multiply”)
print(“4. Divide”)
print(“5. Exit”)
ch = input(“Enter your choice: “)
if ch==“1”:
print(“Addition = “,num1 + num2)
elif ch==“2”:
print(“Difference = “, num1 – num2)
elif ch==“3”:
print(“Multiplication = “, num1 * num2)
elif ch==“4”:
print(“Division = “,num1 / num2)
elif ch==“5”:
break
else:
print(“Invalid Option”)
#
# method 2: Exit controlled
ch = “1”
while ch!=“5”:
num1 = int(input(“Enter first number: “))
num2 = int(input(“Enter second number: “))
print(“Your Option: “)
print(“1. Add”)
print(“2. Subtract”)
print(“3. Multiply”)
print(“4. Divide”)
print(“5. Exit”)
ch = input(“Enter your choice: “)
if ch==“1”:
print(“Addition = “,num1 + num2)
elif ch==“2”:
print(“Difference = “, num1 – num2)
elif ch==“3”:
print(“Multiplication = “, num1 * num2)
elif ch==“4”:
print(“Division = “,num1 / num2)
elif ch==“5”:
print(“Exiting now…”)
else:
print(“Invalid Option”)
##
# method 3: Entry controlled
choice = input(“Enter Yes to perform arithmetic operations: “)
while choice.lower() ==“yes”:
num1 = int(input(“Enter first number: “))
num2 = int(input(“Enter second number: “))
print(“Your Option: “)
print(“1. Add”)
print(“2. Subtract”)
print(“3. Multiply”)
print(“4. Divide”)
print(“5. Exit”)
ch = input(“Enter your choice: “)
if ch==“1”:
print(“Addition = “,num1 + num2)
elif ch==“2”:
print(“Difference = “, num1 – num2)
elif ch==“3”:
print(“Multiplication = “, num1 * num2)
elif ch==“4”:
print(“Division = “,num1 / num2)
elif ch==“5”:
choice =“no”
print(“Exiting now…”)
else:
print(“Invalid Option”)
#
# Generate odd numbers from 1 till user wants to continue
num1 = 1
while True:
print(num1)
num1+=2
ch=input(“Enter y to generate next number or anyother key to stop: “)
if ch!=‘y’:
break
# Generate fibonacci numbers from 1 till user wants to continue
num1 = 0
num2 = 1
while True:
num3 =num1 +num2
print(num3)
num1,num2 = num2,num3
ch=input(“Enter y to generate next number or anyother key to stop: “)
if ch!=‘y’:
break
# Generate fibonacci numbers from 1 till user wants to continue
print(“Hit Enter key to continue or anyother key to stop! “)
num1 = 0
num2 = 1
while True:
num3 =num1 +num2
print(num3,end=“”)
num1,num2 = num2,num3
ch=input()
if ch!=”:
break
print(random.random())
print(random.randint(100,1000))
from random import randint
print(randint(100,1000))
# guess the number game – computer (has the number) v human (attempting)
from random import randint
num = randint(1,100)
attempt=0
while True:
guess = int(input(“Guess the number (1-100): “))
if guess<1 or guess>100:
print(“Invalid attempt!!!”)
continue
attempt+=1 #attempt=attempt+1
if guess ==num:
print(f”Congratulations! You got it right in {attempt} attempts.”)
break
elif guess < num:
print(“Sorry, that’s incorrect. Please try again with a higher number!”)
else:
print(“Sorry, that’s incorrect. Please try again with a lower number!”)
### ###
# guess the number game – computer (has the number) v computer (attempting)
from random import randint
start,stop = 1,100
num = randint(1,100)
attempt=0
while True:
#guess = int(input(“Guess the number (1-100): “))
guess = randint(start,stop)
if guess<1 or guess>100:
print(“Invalid attempt!!!”)
continue
attempt+=1 #attempt=attempt+1
if guess ==num:
print(f”Congratulations! You got it right in {attempt} attempts.”)
break
elif guess < num:
print(f”Sorry, {guess} that’s incorrect. Please try again with a higher number!”)
start=guess+1
else:
print(f”Sorry, {guess} that’s incorrect. Please try again with a lower number!”)
stop=guess-1
##
# guess the number game – computer (has the number) v computer (attempting)
from random import randint
total_attempts = 0
for i in range(10000):
start,stop = 1,100
num = randint(1,100)
attempt=0
while True:
#guess = int(input(“Guess the number (1-100): “))
guess = randint(start,stop)
if guess<1 or guess>100:
print(“Invalid attempt!!!”)
continue
attempt+=1 #attempt=attempt+1
if guess ==num:
print(f”Congratulations! You got it right in {attempt} attempts.”)
total_attempts+=attempt
break
elif guess < num:
print(f”Sorry, {guess} that’s incorrect. Please try again with a higher number!”)
start=guess+1
else:
print(f”Sorry, {guess} that’s incorrect. Please try again with a lower number!”)
stop=guess-1
print(“========================================”)
print(“Average number of attempts = “,total_attempts/10000)
print(“========================================”)
Multi line
text of
comments
which can go into
multiple lines
”’
# Strings
str1 = ‘Hello’
str2 = “Hello there”
print(type(str1), type(str2))
str3 = ”’How are you?
Where are you from?
Where do you want to go?”’
str4 = “””I am fine
I live here
I am going there”””
print(type(str3), type(str4))
print(str3)
print(str4)
# one line of comment
”’
Multi line
text of
comments
which can go into
multiple lines
”’
# what’s your name?
print(‘what\’s your name?’)
# counting in Python starts from zero
str1 = ‘Hello there how are you?’
print(“Number of characters in str1 is”,len(str1))
print(“First character: “,str1[0], str1[-len(str1)])
print(“Second character: “,str1[1])
print(“Last character: “,str1[len(str1)-1])
print(“Last character: “,str1[-1])
print(“Second Last character: “,str1[-2])
print(“5th 6th 7th char: “,str1[4:7])
print(“First 4 char: “,str1[0:4],str1[:4])
print(“first 3 alternate char: “,str1[1:5:2])
print(“last 3 characters:”,str1[-3:])
print(“last 4 but one characters:”,str1[-4:-1])
print(str1[5:1:-1])
txt1 = “HiiH”
txt2=txt1[-1::-1] #reversing the text
print(txt2)
txt2=str1[-1:-7:-1] #reversing the text
print(txt2)
if txt2 == txt1:
print(“Its palindrome”)
else:
print(“Its not a palindrome”)
var1 = 5
#print(var1[0]) # ‘int’ object is not subscriptable
# add two strings
print(“Hello”+“, “+“How are you?”)
print(“Hello”,“How are you?”)
print((“Hello”+” “)*5)
print(“* “*5)
str1 = “hello”
for i in str1:
print(i)
for i in range(len(str1)):
print(i, str1[i])
print(type(str1)) # <class ‘str’>
str2 = “HOW Are You?”
up_count, lo_count,sp_count = 0,0,0
for i in str2:
if i.islower():
lo_count+=1
if i.isupper():
up_count+=1
if i.isspace():
sp_count+=1
print(f”Number of spaces={sp_count}, uppercase letters={up_count} and lower case letters={lo_count}“)
#input values:
val1 = input(“Enter a number: “)
if val1.isdigit():
val1 = int(val1)
print(val1 * 5)
else:
print(“Invalid value”)
str3 = “123af ds”
print(str3.isalnum())
#
str1 =“How are You”
# docs.python.org
help(str.isascii)
help(help)
str1 = “HOw are YOU today?”
print(str1.upper())
print(str1.lower())
print(str1.title())
#str1 = str1.title()
# strings are immutable – you cant edit
#str1[3] = “A” #TypeError: ‘str’ object does not support item assignment
str1= str1[0:3]+“A”+str1[4:]
print(str1)
cnt = str1.lower().count(‘o’)
print(cnt)
cnt = str1.count(‘O’,3,15) # x,start,end
print(cnt)




str1 = “Hello how are you doing today”
var1 = str1.split()
print(“Var 1 =”,var1)
var2 = str1.split(‘o’)
print(“Var 2 =”,var2)
str2 = “1,|Sachin,|Mumbai,|Cricket”
var3 = str2.split(‘,|’)
print(var3)
str11 = ” “.join(var1)
print(“Str11 = “,str11)
str11 = “”.join(var2)
print(“Str11 = “,str11)
str11= “–“.join(var3)
print(“Str11 = “,str11)
# Strings – method
str1 = “Hello how are you doing today”
str2 = str1.replace(‘o’,‘ooo’)
print(str2)
cnt = str1.count(‘z’)
print(“Number of z in the str1 =”,cnt)
find_cnt = str1.find(‘ow’)
if find_cnt==-1:
print(“Given substring is not in the main string”)
else:
print(“Substring in the str1 found at =”,find_cnt)
find_cnt = str1.find(‘o’,5,6)
print(“Substring in the str1 found at =”,find_cnt)
str2 = str1.replace(‘z’,‘ooo’,3)
print(str2)
################
## LIST = Linear Ordered Mutable Collection
l1 = [55, ‘Hello’,False,45.9,[2,4,6]]
print(“type of l1 = “,type(l1))
print(“Number of members in the list=”,len(l1))
print(l1[0],l1[4],l1[-1])
print(“type of l1 =”,type(l1[0]))
print(“type of l1 =”,type(l1[-1]))
l2 = l1[-1]
print(l2[0], l1[-1][0], type(l1[-1][0]))
l1[0] = 95
print(“L1 =”,l1)
## LIST = Linear Ordered Mutable Collection
l1 = [55, ‘Hello’,False,45.9,[2,4,6]]
for member in l1:
print(member)
print(l1+l1)
print(l1*2)
print(“count = “,l1.count(False))
print(“count = “,l1.count(‘Hello’))
# remove second last member – pop takes position
l1.pop(-2)
print(“L1 after Pop: “,l1)
l1.pop(-2)
print(“L1 after Pop: “,l1)
# delete the element – remove takes value
cnt = l1.count(‘Helloo’)
if cnt>0:
l1.remove(‘Helloo’)
print(“L1 after Remove: “,l1)
else:
print(“‘Helloo’ not in the list”)
l1 = [10,50,90,20,90]
# add and remove members
l1.append(25) #append will add at the end
l1.append(45)
print(“L1 after append: “,l1)
#insert takes position and the value to add
l1.insert(2,35)
l1.insert(2,65)
print(“L1 after insert: “,l1)
l1.remove(35) #takes value to delete
l1.remove(90)
print(“L1 after remove: “,l1)
cnt_90 = l1.count(90)
print(“Number of 90s: “,cnt_90)
l1.pop(2) #index at which you want to delete
print(“L1 after pop: “,l1)
# Collections – Lists – linear mutable ordered collection
l1 = [10,50,90,20,90]
l2 = l1.copy() #shallow – photocopy
l3 = l1 # deepcopy – same list with two names
print(“1. L1 = “,l1)
print(“1. L2 = “,l2)
print(“1. L3 = “,l3)
l1.append(11)
l2.append(22)
l3.append(33)
print(“2. L1 = “,l1)
print(“2. L2 = “,l2)
print(“2. L3 = “,l3)
print(“Index of 90:”,l1.index(90,3,7))
# Extend: l1 = l1+l2
l2=[1,2,3]
l1.extend(l2)
print(“L1 after extend:”,l1)
l1.reverse()
print(“L1 after reverse: “,l1)
l1.sort() #sort in ascending order
print(“L1 after sort: “,l1)
l1.sort(reverse=True) #sort in descending order
print(“L1 after reverse sort: “,l1)
l1.clear()
print(“L1 after clear: “,l1)
######## question from Vivek: ###########
l1 = [9,5,7,2]
target = 12
l2=l1.copy()
l2.sort() #[2,5,7,19]
for i in range(len(l2)-1):
if l2[i]+l2[i+1] == target
#l1.index(l2[i]), l1.index(l2[i+1])
break
else:
> target: stop
<target: check with i+1 with i+2
l1 = [2,4,6,8]
print(l1, type(l1))
t1 = (2,4,6,8,2,4,6,2)
print(t1, type(t1))
l1[1] = 14
print(“L1 = “,l1)
#t1[1] = 14 TypeError: ‘tuple’ object does not support item assignment
print(“Index of 2 =”,t1.index(2))
print(“Count of 2 =”,t1.count(2))
print(t1, type(t1))
t1=list(t1)
t1[1] = 14
t1 = tuple(t1)
print(t1, type(t1))
for i in t1:
print(i)
t2 = (3,6,9) #packing
a,b,c = t2 #unpacking
print(a,type(a),b,type(b),c,type(c))
t3 = ()
print(“type of t3=”,type(t3))
t4 = (“Hello”,4)
print(“type of t4=”,type(t4))
# (“Hello” + “World”)*3 -> “Hello” + “World”*3
###############
# Dictionary: unordered mutable collection
# pairs of key:value
d1 = {0:3,1:6,2:9}
print(“type = “,type(d1))
print(d1[1])
basic_health= {“Name”:“Sachin”,
“Weight”:156,
“Age”:42,
23:“NY”}
print(basic_health[“Name”])
patients =[{“Name”:“Sachin”,“Weight”:156,“Age”:42,23:“NY”},
{“Name”:“Virat”,“Weight”:126,“Age”:38,23:“NY”},
{“Name”:“Rohit”,“Weight”:176,“Age”:24,23:“NY”},
{“Name”:“Kapil”,“Weight”:196,“Age”:62,23:“NY”}]
print(patients[1][“Weight”])
basic_health= {“Name”:“Sachin”,
“Weight”:2,
“Age”:2,
“Age”:10,
23:“NY”,
“Age”:15}
print(basic_health.keys())
print(basic_health.values())
print(basic_health.items())
”’
WAP to input marks of three students in three subjects
marks = {‘Sachin’: [78, 87, 69], ‘Kapil’: [59, 79, 49], ‘Virat’: [88, 68, 78]}
”’
students = [‘Sachin’,‘Kapil’,‘Virat’]
subjects = [‘Maths’,‘Science’,‘English’]
marks = {}
#marks_list = []
num_students, num_subjects = 3,3
for i in range(num_students):
marks_list = []
for j in range(num_subjects):
m = int(input(“Enter the marks in subject ” + subjects[j]+” : “))
marks_list.append(m)
temp = {students[i]:marks_list}
marks.update(temp)
#marks_list.clear()
print(“Marks entered are: “,marks)
# Dictionary
”’
WAP to input marks of three students in three subjects.
calculate total and average of marks for all the 3 students
find who is the highest scorer in total and also for each subject
marks = {‘Sachin’: [78, 87, 69], ‘Kapil’: [59, 79, 49], ‘Virat’: [88, 68, 78]}
”’
students = [‘Sachin’, ‘Kapil’, ‘Virat’]
subjects = [‘Maths’, ‘Science’, ‘English’]
marks = {‘Sachin’: [78, 87, 69], ‘Kapil’: [59, 79, 49], ‘Virat’: [88, 68, 78]}
topper = {‘Total’: –1, ‘Name’: []}
subject_highest = [-1, –1, –1]
num_students, num_subjects = 3, 3
for i in range(num_students):
tot, avg = 0, 0
key = students[i]
for j in range(num_subjects):
tot = tot + marks[key][j]
# checking the highest values for each subject
# …
avg = tot / 3
print(f”Total marks obtained by {students[i]} is {tot} and average is {avg:.1f}“)
# check highest total
if tot >= topper[‘Total’]:
topper[‘Total’] = tot
topper[‘Name’].append(key)
print(f”{topper[‘Name’]} has topped the class with total marks of {topper[‘Total’]}“)
”’
WAP to input marks of three students in three subjects.
calculate total and average of marks for all the 3 students
find who is the highest scorer in total and also for each subject
marks = {‘Sachin’: [78, 87, 69], ‘Kapil’: [59, 79, 49], ‘Virat’: [88, 68, 78]}
”’
students = [‘Sachin’,‘Kapil’,‘Virat’]
subjects = [‘Maths’,‘Science’,‘English’]
marks = {‘Sachin’: [78, 87, 69], ‘Kapil’: [59, 79, 49], ‘Virat’: [88, 68, 78]}
topper = {‘Total’:-1, ‘Name’:[]}
subject_highest = [-1,-1,-1]
num_students, num_subjects = 3,3
for i in range(num_students):
tot,avg = 0,0
key = students[i]
for j in range(num_subjects):
tot = tot + marks[key][j]
#checking the highest values for each subject
if marks[key][j] > subject_highest[j]:
subject_highest[j] = marks[key][j]
avg = tot / 3
print(f”Total marks obtained by {students[i]} is {tot} and average is {avg:.1f}“)
# check highest total
if tot >=topper[‘Total’]:
topper[‘Total’] = tot
topper[‘Name’].append(key)
print(f”{topper[‘Name’]} has topped the class with total marks of {topper[‘Total’]}“)
print(f”Highest marks for subjects {subjects} is {subject_highest}“)
marks = {‘Sachin’: [78, 87, 69], ‘Kapil’: [59, 79, 49], ‘Virat’: [88, 68, 78]}
# deep & shallow copy
marks2 = marks
marks3 = marks.copy()
print(“before update:”)
print(“Marks = “,marks)
print(“Marks2 = “,marks2)
print(“Marks3 = “,marks3)
marks2.pop(‘Kapil’)
marks.update({‘Mahi’:[71,91,81]})
print(“after update:”)
print(“Marks = “,marks)
print(“Marks2 = “,marks2)
print(“Marks3 = “,marks3)
###########################
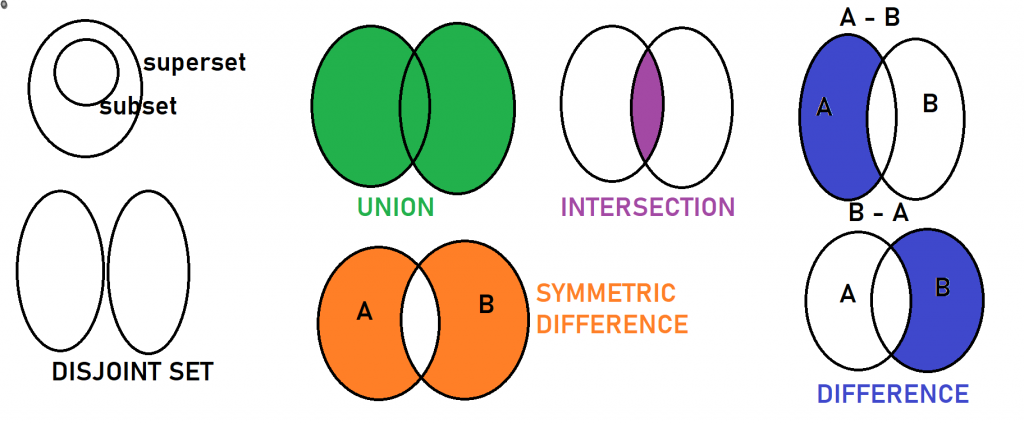
## SETS
# SETS
l1 = [‘Apple’,‘Apple’,‘Apple’,‘Apple’,‘Apple’]
print(“Values in L1 = “,len(l1))
s1 = {‘Apple’,‘Apple’,‘Apple’,‘Apple’,‘Apple’}
print(type(s1))
print(“Values in S1 = “,len(s1))
# property 1: removes duplicate values
s1 = {‘Apple’,‘Banana’,‘Orange’,‘Grapes’,‘Mango’}
s2 = {‘Grapes’,‘Mango’, ‘Guava’,‘Pine apple’,‘Cherry’}
# property 2: order doesnt matter
print(“union – total how many values”)
print(s1|s2)
print(s1.union(s2))
print(“Intersection – common values between the sets”)
print(s1 & s2)
print(s1.intersection(s2))
print(“Difference (minus) – u remove set of values from another set”)
print(s1 – s2)
print(s1.difference(s2))
print(s2 – s1)
print(s2.difference(s1))
print(“Symmetric difference”)
print(s1 ^ s2)
print(s1.symmetric_difference(s2))
##
s1 = {1,2,3,4,5,6}
s2 = {4,5,6}
print(s1.isdisjoint(s2))
print(s1.issuperset(s2))
# sets, lists, tuples -> they are convertible in each others form
l1 = [‘Apple’,‘Apple’,‘Apple’,‘Apple’,‘Apple’]
l1 = list(set(l1))
print(l1)
s1 = {4,2,3}
print(s1)
def smile():
txt=”’ A smile, a curve that sets all right,
Lighting days and brightening the night.
In its warmth, hearts find their flight,
A silent whisper of pure delight.”’
print(txt)
smile()
smile()
smile()
#==================
# function to calculate gross pay
def calc_grosspay():
basic_salary = 5000
hra = 0.1 * basic_salary
da = 0.4 * basic_salary
gross_pay = basic_salary + hra + da
print(“Your gross pay is”,gross_pay)
def calc_grosspay_withreturn():
basic_salary = 5000
hra = 0.1 * basic_salary
da = 0.4 * basic_salary
gross_pay = basic_salary + hra + da
return gross_pay
def calc_grosspay_return_input(basic_salary):
hra = 0.1 * basic_salary
da = 0.4 * basic_salary
gross_pay = basic_salary + hra + da
return gross_pay
bp_list = [3900,5000,6500,9000]
gp_1 = calc_grosspay_return_input(bp_list[3])
print(“Gross Pay for this month is”,gp_1)
gp = calc_grosspay_withreturn()
print(“Total gross pay for ABC is”,gp)
gp_list=[]
gp_list.append(gp)
calc_grosspay()
HOUSENO = 55
def myfunc1():
#x = 51
global x
print(“1 Value of x =”,x)
print(“My House No =”, HOUSENO)
x = 51
print(“2 Value of x =”, x)
def myfunc2(a,b):
print(“======== MYFUNC2 ========”)
print(f”a = {a} and b = {b}“)
print(“Sum of a and b = “,a+b)
def myfunc3(a=5,b=3.14):
print(“======== MYFUNC3 ========”)
print(f”a = {a} and b = {b}“)
print(“Sum of a and b = “,a+b)
def myfunc4(a,b):
print(“======== MYFUNC4 ========”)
print(f”a = {a} and b = {b}“)
print(“Sum of a and b = “,a+b)
def myfunc5(a,*b):
print(“a = “,a)
print(“b = “, b)
def myfunc6(a,*b, **c):
print(“a = “,a)
print(“b = “, b)
print(“c = “, c)
# default arguments (there is a default value added)
myfunc3(10,20)
myfunc3(10)
myfunc3()
# required positional arguments
myfunc2(10,20)
x = 5
myfunc1()
print(“Value of x =”,x)
# non-positional = keyword arguments
myfunc4(b=22, a=33)
# variable length arguments
myfunc5(10,20,30,40)
myfunc5(10)
myfunc5(10, 20)
myfunc6(10, 20,“hello”,name=“Sachin”,runs=3000,city=“Mumbai”)
”’
10 = 2 to 5
7 = 2,
9 = 2,3
”’
def gen_prime(num):
”’
This function takes a parameter and checks if its a prime number or not
:param num: number (int)
:return: True/False (True for prime number)
”’
isPrime = True
for i in range(2,num//2):
if num%i ==0:
isPrime = False
break
return isPrime
if __name__ ==“__main__”:
num = 11
print(num,” : “,gen_prime(num))
num = 100
print(num,” : “,gen_prime(num))
# generate prime numbers between given range
start,end = 1000, 5000
for i in range(start,end):
check = gen_prime(i)
if check:
print(i,end=“, “)
# doc string: multi line comment added at the beginning of the function
help(gen_prime)
from infy_apr import gen_prime
def product_val(n1,n2):
return n1 * n2
if __name__==“__main__”:
num1 = 1
num2 = 3
print(“Sum of two numbers is”,num2+num1)
# generate prime numbers between 50K to 50.5K
for i in range(50000,50500):
check = gen_prime(i)
if check:
print(i,end=“, “)
”’
O -> L1 (20) -> L1(19) -> L1(18) … -> 1 -> 1
”’
def sayhi(n):
if n>0:
print(“Hello”)
sayhi(n-1)
else:
return 1
sayhi(20)
”’
Factorial of a number:
5! = 5 * 4 * 3 * 2 * 1
”’
def facto(n):
if n<=1:
return 1
else:
return n * facto(n-1)
result = facto(5)
print(“Factorial is”,result)
#############
def f1():
def f2():
print(“I am in f2 which is inside f1”)
print(“first line of f1”)
f2()
print(“second line of f1”)
def calculate(n1,n2,op):
def plus(n1,n2):
return n1 + n2
def diff(n1,n2):
return n1-n2
if op==“+”:
output = plus(n1,n2)
if op==“-“:
output = diff(n1, n2)
return output
res = calculate(5,10,“+”)
print(“1. Result = “,res)
res = calculate(5,10,“-“)
print(“2. Result = “,res)
####################
def plus(n1,n2):
return n1 + n2
def diff(n1,n2):
return n1-n2
def calculate(n1,n2,func):
output = func(n1,n2)
return output
res = calculate(5,10,plus)
print(“1. Result = “,res)
res = calculate(5,10,diff)
print(“2. Result = “,res)
###############
# in-built functions()
# user defined functions()
# anonymous / one line /lambda
def myfunc1(a,b):
return a**b
#above myfunc1() can also be written as:
myfunc2 = lambda a,b: a**b
print(“5 to power of 4 is”,myfunc2(5,4))
”’
map: apply same logic on all the values of the list: multiply all the values by 76
filter: filter out values in a list based on a condition: remove -ve values
reduce: reduce multiple values in a list to a single value
”’
# a= 11, b = 12, c = 13…
calc = 0
list1 = [‘a’,‘b’,‘c’,‘d’]
word = input()
for i in word:
calc = calc+list1.index(i) + 11 # 11 + 13+14
print(calc)
”’
O -> L1 (20) -> L1(19) -> L1(18) … -> 1 -> 1
”’
def sayhi(n):
if n>0:
print(“Hello”)
sayhi(n-1)
else:
return 1
sayhi(20)
”’
Factorial of a number:
5! = 5 * 4 * 3 * 2 * 1
”’
def facto(n):
if n<=1:
return 1
else:
return n * facto(n-1)
result = facto(5)
print(“Factorial is”,result)
#############
def f1():
def f2():
print(“I am in f2 which is inside f1”)
print(“first line of f1”)
f2()
print(“second line of f1”)
def calculate(n1,n2,op):
def plus(n1,n2):
return n1 + n2
def diff(n1,n2):
return n1-n2
if op==“+”:
output = plus(n1,n2)
if op==“-“:
output = diff(n1, n2)
return output
res = calculate(5,10,“+”)
print(“1. Result = “,res)
res = calculate(5,10,“-“)
print(“2. Result = “,res)
####################
def plus(n1,n2):
return n1 + n2
def diff(n1,n2):
return n1-n2
def calculate(n1,n2,func):
output = func(n1,n2)
return output
res = calculate(5,10,plus)
print(“1. Result = “,res)
res = calculate(5,10,diff)
print(“2. Result = “,res)
###############
# in-built functions()
# user defined functions()
# anonymous / one line /lambda
def myfunc1(a,b):
return a**b
#above myfunc1() can also be written as:
myfunc2 = lambda a,b: a**b
print(“5 to power of 4 is”,myfunc2(5,4))
”’
map: apply same logic on all the values of the list: multiply all the values by 76
filter: filter out values in a list based on a condition: remove -ve values
reduce: reduce multiple values in a list to a single value
”’
# a= 11, b = 12, c = 13…
calc = 0
list1 = [‘a’,‘b’,‘c’,‘d’]
word = input()
for i in word:
calc = calc+list1.index(i) + 11 # 11 + 13+14
print(calc)
map: apply same logic on all the values of the list: multiply all the values by 76
filter: filter out values in a list based on a condition: remove -ve values
reduce: reduce multiple values in a list to a single value
”’
value_usd = [12.15,34.20,13,8,9,12,45,87,56,78,54,34]
value_inr = []
# 1 usd = 78 inr
for v in value_usd:
value_inr.append(v*78)
print(“Value in INR: “,value_inr)
value_inr =list(map(lambda x: 78*x,value_usd))
print(“Value in INR: “,value_inr)
# filter: filter out the values
new_list=[12,7,0,-5,-6,15,18,21,-44,-90,-34,56,43,12,7,0,-5,-6,15,18,21,-44,-90,-34,56,43]
output_list = list(filter(lambda x: x>=0,new_list))
print(“Filtered: “,output_list)
output_list = list(filter(lambda x: x%3==0 and x>=0,new_list))
print(“Filtered: “,output_list)
# reduce
import functools as ft
#from functools import reduce
new_list=[12,7,0,-5,-6,15,18,21,-44,-90,-34,56,43]
val = ft.reduce(lambda x,y:x+y,new_list)
print(“Value after reduce = “,val)
”’
x+y => [12,7,0,-5,-6,15,18,21,-44,-90,-34,56,43]
12+7
19+0
19+ -5
14 + -6
8+15
”’
abc = lambda x,y:x+y
def abc(x,y):
return x+y
##################################
## class & objects
”’
car – class
number of wheels – 4, color, make
driving
parking
”’
class Book:
number_of_books = 0
def reading(self):
print(“I am reading a book”)
b1 = Book() #creating object of class Book
b2 = Book()
b3 = Book()
b4 = Book()
print(b1.number_of_books)
b1.reading()
”’
class level variables and methods
object level variables and methods
”’
__init__() : will automatically called when object is created
”’
class Book:
book_count = 0 # class level variable
def __init__(self,title): # object level method
self.title=title # object level variable
total = 0 #normal variable
Book.book_count+=1
@classmethod
def output(cls):
print(“Total book now available = “, Book.book_count)
b1 = Book(“Python Programming”)
b2 = Book(“SQL Programming”)
b3 = Book(“”)
print(type(b1))
#############
print(“Printing book_count: “)
print(b1.book_count)
print(b2.book_count)
print(b3.book_count)
print(Book.book_count)
print(“Printing output:”)
b1.output()
b2.output()
b3.output()
Book.output()
print(“Printing Title”)
print(“B1 title: “, b1.title)
print(“B2 title: “, b2.title)
print(“B3 title: “, b3.title)
#print(Book.title) AttributeError: type object ‘Book’ has no attribute ‘title’
##############
class MyMathOp:
def __init__(self,a,b):
self.n1 = a
self.n2 = b
def add_numbers(self):
self.total = self.n1 + self.n2
def subtract_numbers(self):
self.subtract = self.n1 – self.n2
def check_prime(self):
# check if n1 is prime or not
self.checkPrime = True
for i in range(2, self.n1//2+1):
if self.n1 % i==0:
self.checkPrime=False
m1 = MyMathOp(15,10)
print(m1.n1)
m1.check_prime()
print(m1.checkPrime)
Encapsulation: information hiding – creating class
Abstraction: implementation hiding
Inheritance: inheritance properties from another class
Polymorphism: having multiple forms
”’
class Shape:
def __init__(self,s1=0,s2=0,s3=0,s4=0):
self.s1 = s1
self.s2 = s2
self.s3 = s3
self.s4 = s4
self.area = –1
self.surfacearea = –1
def print_val(self):
if self.s1>0:
print(“Side 1 = “,self.s1)
if self.s2>0:
print(“Side 2 = “,self.s2)
if self.s3>0:
print(“Side 3 = “,self.s3)
if self.s4>0:
print(“My Side 4 = “,self.s4)
def myarea(self):
print(“Area is not implemented!”)
”’
def mysurfacearea(self):
print(“Suraface area is not implemented!”)
”’
class Rectangle(Shape):
def __init__(self,s1,s2):
Shape.__init__(self,s1,s2)
def myarea(self):
print(“Area is”,self.s1*self.s2)
class Circle(Shape):
def __init__(self,s1):
Shape.__init__(self,s1)
def myarea(self):
print(“Area is”,3.14*self.s1*self.s2)
r1 = Rectangle(34,45)
r1.print_val()
r1.myarea()
c1 = Circle(12)
c1.print_val()
c1.myarea()
Encapsulation: information hiding – creating class
Abstraction: implementation hiding
Inheritance: inheritance properties from another class
Polymorphism: having multiple forms
”’
class Shape:
def __init__(self,s1=0,s2=0,s3=0,s4=0):
self.s1 = s1
self.s2 = s2
self.s3 = s3
self.s4 = s4
self.area = –1
self.surfacearea = –1
def print_val(self):
if self.s1>0:
print(“Side 1 = “,self.s1)
if self.s2>0:
print(“Side 2 = “,self.s2)
if self.s3>0:
print(“Side 3 = “,self.s3)
if self.s4>0:
print(“My Side 4 = “,self.s4)
def myarea(self):
print(“Area is not implemented!”)
def myarea(self,s1):
pass
def myarea(self,s1,s2):
pass
def mysurfacearea(self):
print(“Suraface area is not implemented!”)
def dummy1(self): #public member
print(“Shape.Dummy1”)
def _dummy2(self): # protected
print(“Shape.Dummy2”)
def __dummy3(self): # protected
print(“Shape.Dummy2”)
def dummy4(self):
Shape.__dummy3(self)
class Rectangle(Shape):
def __init__(self,s1,s2):
Shape.__init__(self,s1,s2)
def myarea(self):
print(“Area is”,self.s1*self.s2)
class Circle(Shape):
def __init__(self,s1):
Shape.__init__(self,s1)
def myarea(self):
print(“Area is”,3.14*self.s1*self.s2)
class Cuboid(Rectangle):
def something(self):
print(“In Cuboid”)
class AnotherShape:
def test1(self):
print(“AnotherShape.test1”)
Shape.dummy1(self)
Shape._dummy2(self)
#Shape.__dummy3(self)
r1 = Rectangle(34,45)
r1.print_val()
r1.myarea()
c1 = Circle(12)
c1.print_val()
c1.myarea()
s1 = Shape()
#s1.myarea()
#s1.myarea(10)
#s1.area(10,20)
as1 = AnotherShape()
as1.test1()
”’
public: anyone can call public members of a class
protected (_var): (concept exists but practically it doesnt exist) – behaves like public
concept: only the derived class call
private (__var): available only within the given class
”’
#s1.__dummy3()
#r1.__dummy3()
s1.dummy4()
# syntax error
print(“hello”)
# logical error
# runtime errors – exceptions
a = 50
try:
b = int(input(“Enter the denominator: “))
except ValueError:
print(“You have provided invalid value for B, changing the value to 1”)
b = 1
try:
print(a/b) # ZeroDivisionError
print(“A by B is”,a/b)
except ZeroDivisionError:
print(“Sorry, we cant perform the analysis as denominator is zero”)
print(“thank you”)
################
a = 50
b = input(“Enter the denominator: “)
try:
print(“A by B is”, a / int(b)) # ZeroDivisionError & ValueError
except ValueError:
print(“You have provided invalid value for B, changing the value to 1”)
b = 1
except ZeroDivisionError:
print(“Sorry, we cant perform the analysis as denominator is zero”)
except Exception:
print(“An error has occurred, hence skipping this section”)
else:
print(“So we got the answer now!”)
finally:
print(“Not sure if there was an error but we made it through”)
print(“thank you”)
”’
Working with Text files:
1. read: read(), readline(), readlines()
2. write: write(), writelines()
3. append
Modes: r,r+, w, w+, a, a+
Accessing the file:
1. Absolute path:
2. Relative path:
”’
path=“C:/Folder1/Folder2/txt1.txt”
path=“C:\\Folder1\\Folder2\\txt1.txt”
path=“ptxt1.txt”
content=”’Twinkle twinkle little star
How I wonder what you are
Up above the world so high
like a diamond in the sky
”’
file_obj = open(path,“a+”)
file_obj.write(content)
file_obj.seek(0) # go to the beginning of the content
read_cnt = file_obj.read()
file_obj.close()
print(read_cnt)
#################
path=“ptxt1.txt”
file_obj = open(path,“r”)
read_cnt = file_obj.read()
print(“============”)
print(read_cnt)
file_obj.seek(0)
read_cnt = file_obj.read(10)
print(“============”)
print(read_cnt)
read_cnt = file_obj.readline()
print(“============”)
print(read_cnt)
read_cnt = file_obj.readline(10000)
print(“============”)
print(read_cnt)
file_obj.close()
################
path=“ptxt1.txt”
file_obj = open(path,“r+”)
file_cnt = file_obj.readlines()
print(file_cnt)
file_obj.close()
file_obj = open(path,“w”)
write_nt = [‘Hello how are you?\n‘,‘I am fine\n‘,‘Where are you going\n‘,‘sipdfjisdjisdjf\n‘]
file_obj.writelines(write_nt)
file_obj.close()