Restricted Boltzmann Machine and Its Application
A restricted Boltzmann machine (RBM) is a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs. Restricted Boltzmann machines can also be used in deep learning networks. In particular, deep belief networks can be formed by “stacking” RBMs and optionally fine-tuning the resulting deep network with gradient descent and backpropagation. This deep learning algorithm became very popular after the Netflix Competition where RBM was used as a collaborative filtering technique to predict user ratings for movies and beat most of its competition. It is useful for regression, classification, dimensionality reduction, feature learning, topic modelling and collaborative filtering.
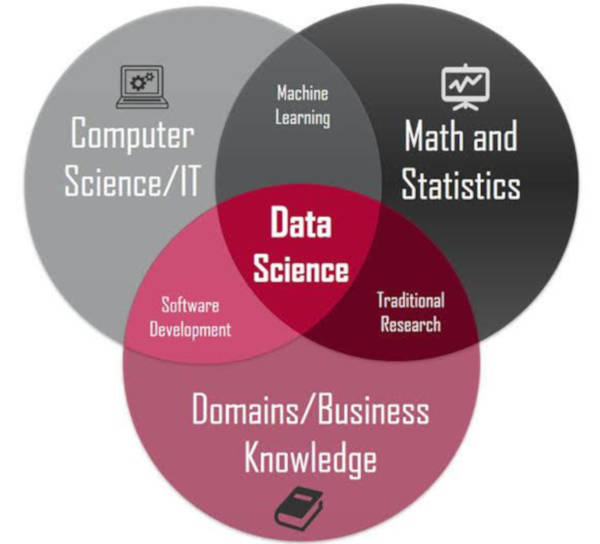
Restricted Boltzmann Machines are stochastic two layered neural networks which belong to a category of energy based models that can detect inherent patterns automatically in the data by reconstructing input. They have two layers visible and hidden. Visible layer has input nodes (nodes which receive input data) and the hidden layer is formed by nodes which extract feature information from the data and the output at the hidden layer is a weighted sum of input layers. They don’t have any output nodes and they don’t have typical binary output through which patterns are learnt. The learning process happens without that capability which makes them different. We only take care of input nodes and don’t worry about hidden nodes. Once the input is provided, RBM’s automatically capture all the patterns, parameters and correlation among the data.
What is Boltzman Machine?
Let’s first undertand what’s Boltzman Machine. Boltzmann Machine was first invented in 1985 by Geoffrey Hinton, a professor at the University of Toronto. He is a leading figure in the deep learning community and is referred to by some as the “Godfather of Deep Learning”.
- Boltzmann Machine is a generative unsupervised model, which involves learning a probability distribution from an original dataset and using it to make inferences about never before seen data.
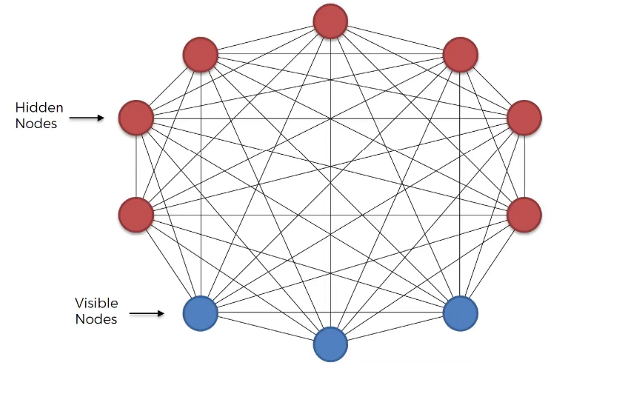
- Boltzmann Machine has an input layer (also referred to as the visible layer) and one or several hidden layers (also referred to as the hidden layer).
- Boltzmann Machine uses neural networks with neurons that are connected not only to other neurons in other layers but also to neurons within the same layer.
- Everything is connected to everything. Connections are bidirectional, visible neurons connected to each other and hidden neurons also connected to each other
- Boltzmann Machine doesn’t expect input data, it generates data. Neurons generate information regardless they are hidden or visible.
- For Boltzmann Machine all neurons are the same, it doesn’t discriminate between hidden and visible neurons. For Boltzmann Machine whole things are system and its generating state of the system.
In Boltzmann Machine, we use our training data and feed into the Boltzmann Machine as input to help the system adjust its weights. It resembles our system not any such system in the world. It learns from the input, what are the possible connections between all these parameters, how do they influence each other and therefore it becomes a machine that represents our system. Boltzmann Machine consists of a neural network with an input layer and one or several hidden layers. The neurons in the neural network make stochastic decisions about whether to turn on or off based on the data we feed during training and the cost function the Boltzmann Machine is trying to minimize. By doing so, the Boltzmann Machine discovers interesting features about the data, which help model the complex underlying relationships and patterns present in the data.
This Boltzmann Machine uses neural networks with neurons that are connected not only to other neurons in other layers but also to neurons within the same layer. That makes training an unrestricted Boltzmann machine very inefficient and Boltzmann Machine had very little commercial success.
Boltzmann Machines are primarily divided into two categories: Energy-based Models (EBMs) and Restricted Boltzmann Machines (RBM). When these RBMs are stacked on top of each other, they are known as Deep Belief Networks (DBN). Our focus of discussion here is the RBM.
Restricted Boltzmann Machines (RBM)
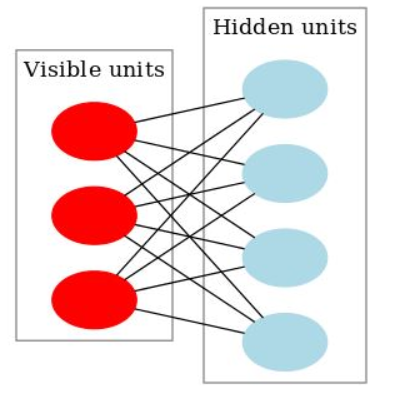
- What makes RBMs different from Boltzmann machines is that visible node isn’t connected to each other, and hidden nodes aren’t connected with each other. Other than that, RBMs are exactly the same as Boltzmann machines.
- It is a probabilistic, unsupervised, generative deep machine learning algorithm.
- RBM’s objective is to find the joint probability distribution that maximizes the log-likelihood function.
- RBM is undirected and has only two layers, Input layer, and hidden layer
- All visible nodes are connected to all the hidden nodes. RBM has two layers, visible layer or input layer and hidden layer so it is also called an asymmetrical bipartite graph.
- No intralayer connection exists between the visible nodes. There is also no intralayer connection between the hidden nodes. There are connections only between input and hidden nodes.
- The original Boltzmann machine had connections between all the nodes. Since RBM restricts the intralayer connection, it is called a Restricted Boltzmann Machine.
- Since RBMs are undirected, they don’t adjust their weights through gradient descent and backpropagation. They adjust their weights through a process called contrastive divergence. At the start of this process, weights for the visible nodes are randomly generated and used to generate the hidden nodes. These hidden nodes then use the same weights to reconstruct visible nodes. The weights used to reconstruct the visible nodes are the same throughout. However, the generated nodes are not the same because they aren’t connected to each other.
Simple Understanding of RBM
Problem Statement: Let’s take an example of a small café just across a street where people come in the evening to hang out. We see that normally three people: Geeta, Meeta and Paavit visit frequently. Not always all of them show up together. We have all the possible combinations of these three people showing up. It could be just Geeta, Meeta or Paavit show up or Geeta and Meeta come at the same time or Paavit and Meeta or Paavit and Geeta or all three of them show up or none of them show up on some days. All the possibilities are valid.

Let’s say, you watch them coming everyday and make a note of it. Let’s take first day, Meeta and Geeta comes and Paavit didn’t. Second day, Paavit comes but Geeta and Meeta doesn’t. After noticing for 15 days, you find that only these two possibilities are repeated. As represented in the table.
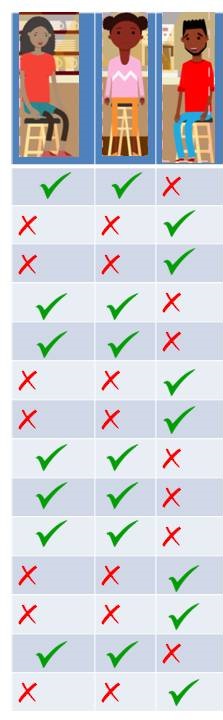
That’s an interesting finding and more so when we come to know that these three people are totally unknown to each other. You also find out that there are two café managers: Ratish and Satish. Lets tabulate it again with 5 people now (3 visitors and 2 managers).
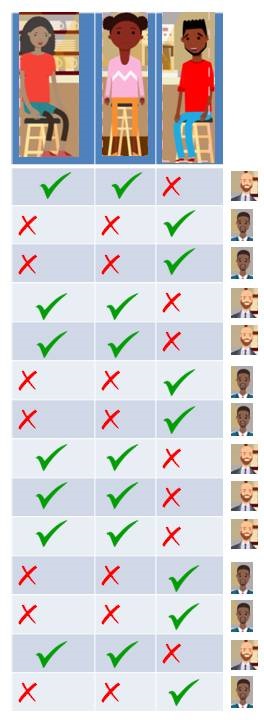
We find that, Geeta and Meeta likes Ratish so they show up when Ratish is on duty. Paavit likes Satish so he shows up only when Satish is on duty. So, we look at the data we might say that Geeta and Meeta went to the café on the days Ratish is on duty and Paavit went when Satish is on duty. Lets add some weights.
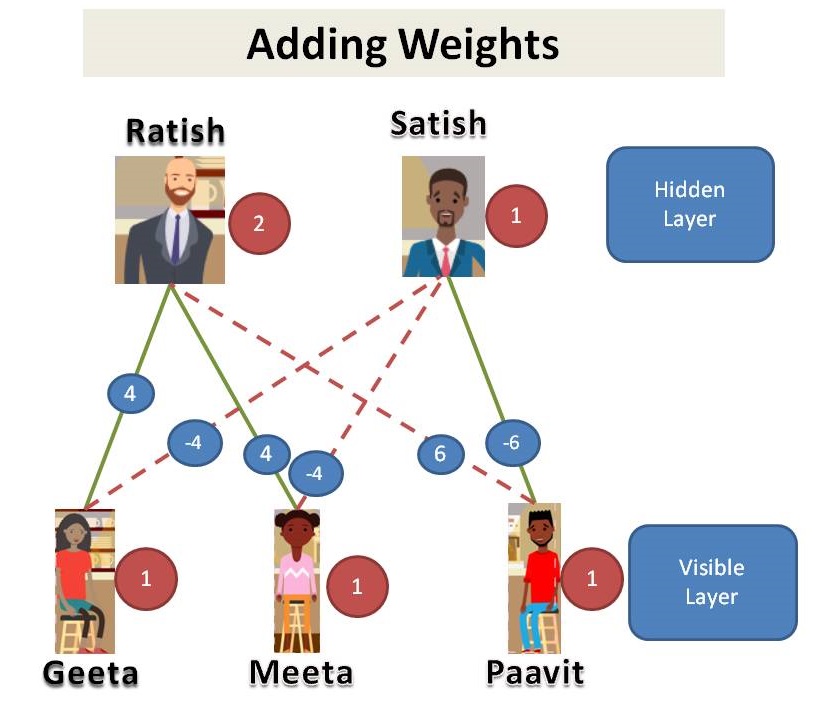
Since we see that customers in our dataset, we call them as visible layer. Managers are not shown in the dataset, we call it as hidden layer. This is an example of Restricted Boltzmann Machine (RBM).
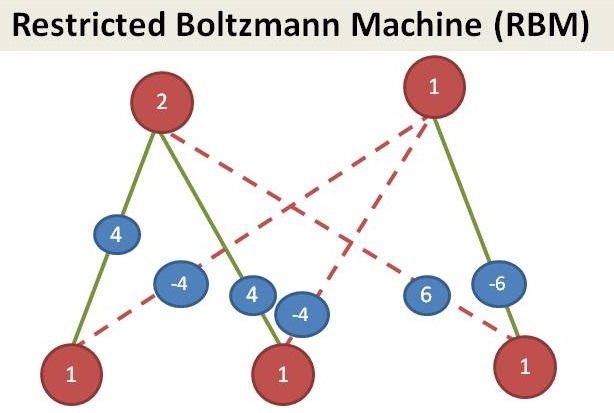
(… to be continued…)
Working of RBM
RBM is a Stochastic Neural Network which means that each neuron will have some random behavior when activated. There are two other layers of bias units (hidden bias and visible bias) in an RBM. This is what makes RBMs different from autoencoders. The hidden bias RBM produces the activation on the forward pass and the visible bias helps RBM to reconstruct the input during a backward pass. The reconstructed input is always different from the actual input as there are no connections among the visible units and therefore, no way of transferring information among themselves.
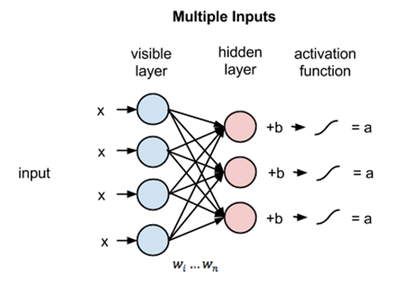
The above image shows the first step in training an RBM with multiple inputs. The inputs are multiplied by the weights and then added to the bias. The result is then passed through a sigmoid activation function and the output determines if the hidden state gets activated or not. Weights will be a matrix with the number of input nodes as the number of rows and the number of hidden nodes as the number of columns. The first hidden node will receive the vector multiplication of the inputs multiplied by the first column of weights before the corresponding bias term is added to it.
Here is the formula of the Sigmoid function shown in the picture:
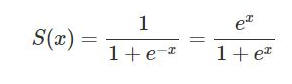
So the equation that we get in this step would be,
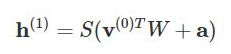
where h(1) and v(0) are the corresponding vectors (column matrices) for the hidden and the visible layers with the superscript as the iteration v(0) means the input that we provide to the network) and a is the hidden layer bias vector.
(Note that we are dealing with vectors and matrices here and not one-dimensional values.)
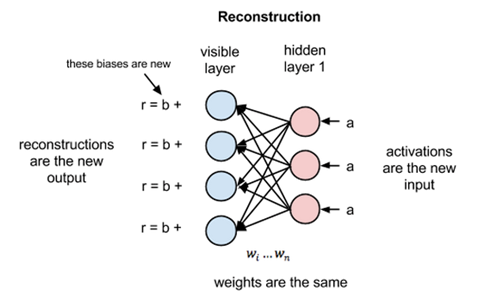
Now this image shows the reverse phase or the reconstruction phase. It is similar to the first pass but in the opposite direction. The equation comes out to be:

where v(1) and h(1) are the corresponding vectors (column matrices) for the visible and the hidden layers with the superscript as the iteration and b is the visible layer bias vector.
Now, the difference v(0)−v(1) can be considered as the reconstruction error that we need to reduce in subsequent steps of the training process. So the weights are adjusted in each iteration so as to minimize this error and this is what the learning process essentially is.
In the forward pass, we are calculating the probability of output h(1) given the input v(0) and the weights W denoted by:

And in the backward pass, while reconstructing the input, we are calculating the probability of output v(1) given the input h(1) and the weights W denoted by:
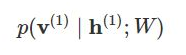
The weights used in both the forward and the backward pass are the same. Together, these two conditional probabilities lead us to the joint distribution of inputs and the activations:

Reconstruction is different from regression or classification in that it estimates the probability distribution of the original input instead of associating a continuous/discrete value to an input example. This means it is trying to guess multiple values at the same time. This is known as generative learning as opposed to discriminative learning that happens in a classification problem (mapping input to labels).
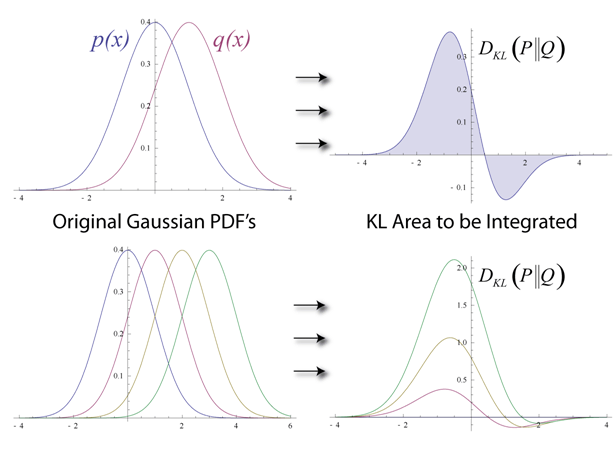
Let us try to see how the algorithm reduces loss or simply put, how it reduces the error at each step. Assume that we have two normal distributions, one from the input data (denoted by p(x)) and one from the reconstructed input approximation (denoted by q(x)). The difference between these two distributions is our error in the graphical sense and our goal is to minimize it, i.e., bring the graphs as close as possible. This idea is represented by a term called the Kullback–Leibler divergence.
KL-divergence measures the non-overlapping areas under the two graphs and the RBM’s optimization algorithm tries to minimize this difference by changing the weights so that the reconstruction closely resembles the input. The graphs on the right-hand side show the integration of the difference in the areas of the curves on the left.
This gives us intuition about our error term. Now, to see how actually this is done for RBMs, we will have to dive into how the loss is being computed. All common training algorithms for RBMs approximate the log-likelihood gradient given some data and perform gradient ascent on these approximations.
Contrastive Divergence
Here is the pseudo-code for the CD algorithm:

Applications:
* Pattern recognition : RBM is used for feature extraction in pattern recognition problems where the challenge is to understand the hand written text or a random pattern.
* Recommendation Engines : RBM is widely used for collaborating filtering techniques where it is used to predict what should be recommended to the end user so that the user enjoys using a particular application or platform. For example : Movie Recommendation, Book Recommendation
* Radar Target Recognition : Here, RBM is used to detect intra pulse in Radar systems which have very low SNR and high noise.
Source: wikipedia (https://en.wikipedia.org/wiki/Restricted_Boltzmann_machine)