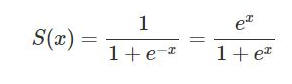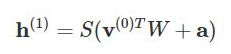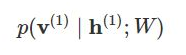A restricted Boltzmann machine (RBM) is a generative stochastic artificial neural network that can learn a probability distribution over its set of inputs. Restricted Boltzmann machines can also be used in deep learning networks. In particular, deep belief networks can be formed by “stacking” RBMs and optionally fine-tuning the resulting deep network with gradient descent and backpropagation. This deep learning algorithm became very popular after the Netflix Competition where RBM was used as a collaborative filtering technique to predict user ratings for movies and beat most of its competition. It is useful for regression, classification, dimensionality reduction, feature learning, topic modelling and collaborative filtering.
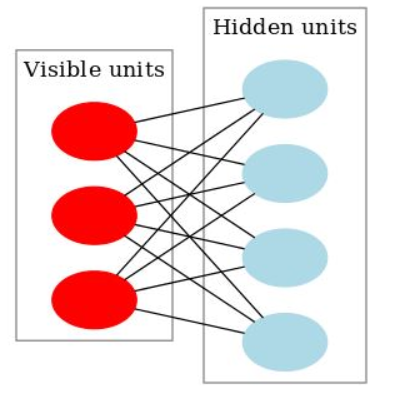
Restricted Boltzmann Machines are stochastic two layered neural networks which belong to a category of energy based models that can detect inherent patterns automatically in the data by reconstructing input. They have two layers visible and hidden. Visible layer has input nodes (nodes which receive input data) and the hidden layer is formed by nodes which extract feature information from the data and the output at the hidden layer is a weighted sum of input layers. They don’t have any output nodes and they don’t have typical binary output through which patterns are learnt. The learning process happens without that capability which makes them different. We only take care of input nodes and don’t worry about hidden nodes. Once the input is provided, RBM’s automatically capture all the patterns, parameters and correlation among the data.
What is Boltzman Machine?
Let’s first undertand what’s Boltzman Machine. Boltzmann Machine was first invented in 1985 by Geoffrey Hinton, a professor at the University of Toronto. He is a leading figure in the deep learning community and is referred to by some as the “Godfather of Deep Learning”.
Boltzman Machine
Boltzmann Machine is a generative unsupervised model, which involves learning a probability distribution from an original dataset and using it to make inferences about never before seen data.
Boltzmann Machine has an input layer (also referred to as the visible layer) and one or several hidden layers (also referred to as the hidden layer).
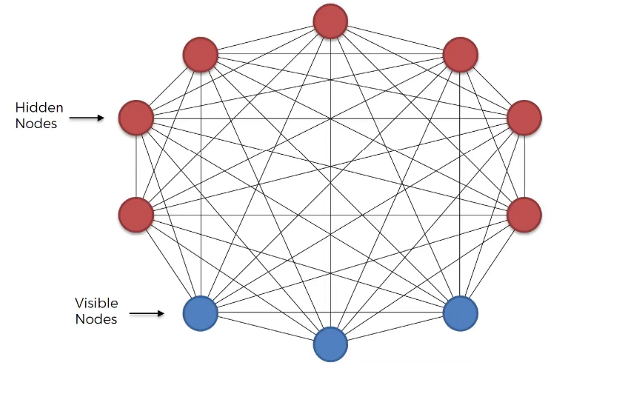
Boltzmann Machine uses neural networks with neurons that are connected not only to other neurons in other layers but also to neurons within the same layer.
Everything is connected to everything. Connections are bidirectional, visible neurons connected to each other and hidden neurons also connected to each other
Boltzmann Machine doesn’t expect input data, it generates data. Neurons generate information regardless they are hidden or visible.
For Boltzmann Machine all neurons are the same, it doesn’t discriminate between hidden and visible neurons. For Boltzmann Machine whole things are system and its generating state of the system.
In Boltzmann Machine, we use our training data and feed into the Boltzmann Machine as input to help the system adjust its weights. It resembles our system not any such system in the world. It learns from the input, what are the possible connections between all these parameters, how do they influence each other and therefore it becomes a machine that represents our system. Boltzmann Machine consists of a neural network with an input layer and one or several hidden layers. The neurons in the neural network make stochastic decisions about whether to turn on or off based on the data we feed during training and the cost function the Boltzmann Machine is trying to minimize. By doing so, the Boltzmann Machine discovers interesting features about the data, which help model the complex underlying relationships and patterns present in the data.
This Boltzmann Machine uses neural networks with neurons that are connected not only to other neurons in other layers but also to neurons within the same layer. That makes training an unrestricted Boltzmann machine very inefficient and Boltzmann Machine had very little commercial success. Boltzmann Machines are primarily divided into two categories: Energy-based Models (EBMs) and Restricted Boltzmann Machines (RBM). When these RBMs are stacked on top of each other, they are known as Deep Belief Networks (DBN). Our focus of discussion here is the RBM.
Restricted Boltzmann Machines (RBM)
Restricted Boltzman Machine Algorithm
What makes RBMs different from Boltzmann machines is that visible node isn’t connected to each other, and hidden nodes aren’t connected with each other. Other than that, RBMs are exactly the same as Boltzmann machines.
It is a probabilistic, unsupervised, generative deep machine learning algorithm.
RBM’s objective is to find the joint probability distribution that maximizes the log-likelihood function.
RBM is undirected and has only two layers, Input layer, and hidden layer
All visible nodes are connected to all the hidden nodes. RBM has two layers, visible layer or input layer and hidden layer so it is also called an asymmetrical bipartite graph.
No intralayer connection exists between the visible nodes. There is also no intralayer connection between the hidden nodes. There are connections only between input and hidden nodes.
The original Boltzmann machine had connections between all the nodes. Since RBM restricts the intralayer connection, it is called a Restricted Boltzmann Machine.
Since RBMs are undirected, they don’t adjust their weights through gradient descent and backpropagation. They adjust their weights through a process called contrastive divergence. At the start of this process, weights for the visible nodes are randomly generated and used to generate the hidden nodes. These hidden nodes then use the same weights to reconstruct visible nodes. The weights used to reconstruct the visible nodes are the same throughout. However, the generated nodes are not the same because they aren’t connected to each other.
Simple Understanding of RBM
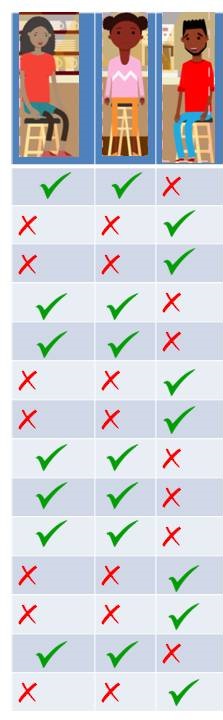
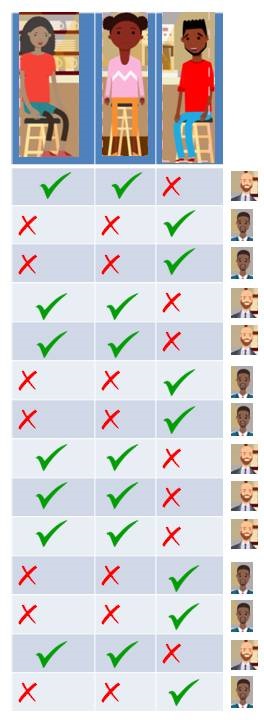
Problem Statement: Let’s take an example of a small café just across a street where people come in the evening to hang out. We see that normally three people: Geeta, Meeta and Paavit visit frequently. Not always all of them show up together. We have all the possible combinations of these three people showing up. It could be just Geeta, Meeta or Paavit show up or Geeta and Meeta come at the same time or Paavit and Meeta or Paavit and Geeta or all three of them show up or none of them show up on some days. All the possibilities are valid.
Left to Right: Geeta, Meeta, Paavit
Let’s say, you watch them coming everyday and make a note of it. Let’s take first day, Meeta and Geeta comes and Paavit didn’t. Second day, Paavit comes but Geeta and Meeta doesn’t. After noticing for 15 days, you find that only these two possibilities are repeated. As represented in the table.
Visits of Geeta, Meeta and Paavit to the cafe
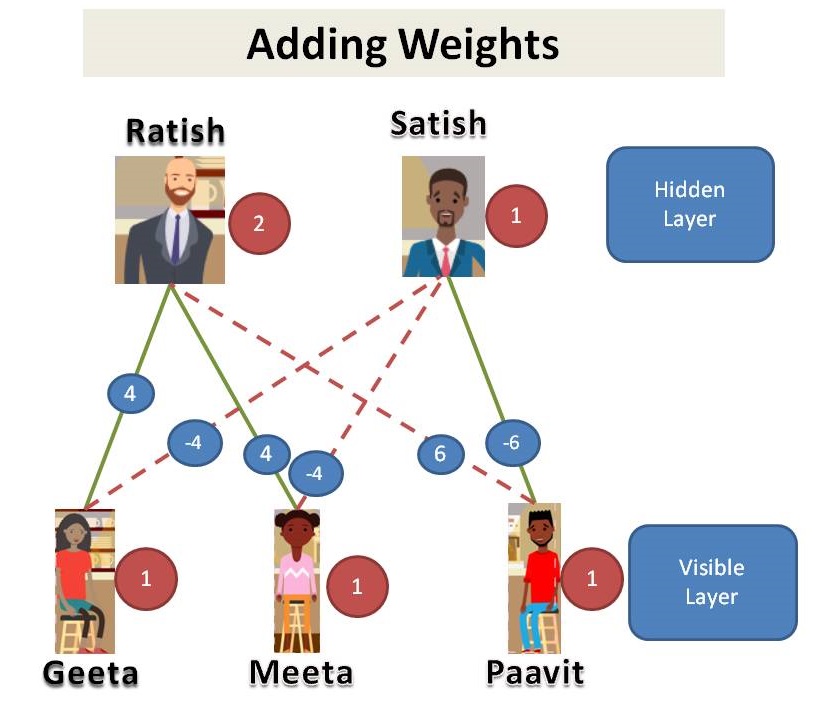
That’s an interesting finding and more so when we come to know that these three people are totally unknown to each other. You also find out that there are two café managers: Ratish and Satish. Lets tabulate it again with 5 people now (3 visitors and 2 managers).
Visits of customer and presence of manager on duty
We find that, Geeta and Meeta likes Ratish so they show up when Ratish is on duty. Paavit likes Satish so he shows up only when Satish is on duty. So, we look at the data we might say that Geeta and Meeta went to the café on the days Ratish is on duty and Paavit went when Satish is on duty. Lets add some weights.
Customers and Managers relation with weights
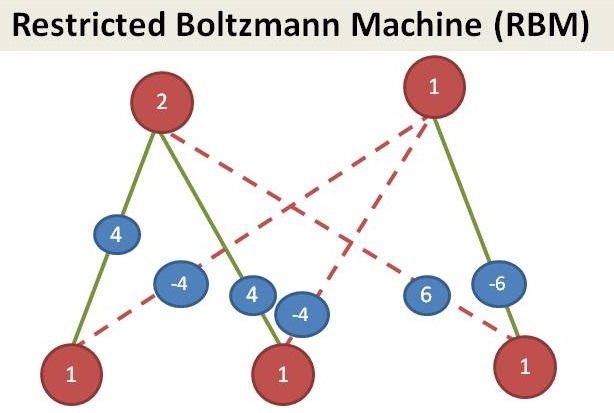
Since we see that customers in our dataset, we call them as visible layer. Managers are not shown in the dataset, we call it as hidden layer. This is an example of Restricted Boltzmann Machine (RBM).
RBM
(… to be continued…)
Working of RBM
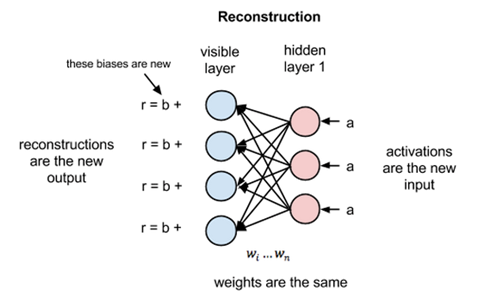
RBM is a Stochastic Neural Network which means that each neuron will have some random behavior when activated. There are two other layers of bias units (hidden bias and visible bias) in an RBM. This is what makes RBMs different from autoencoders. The hidden bias RBM produces the activation on the forward pass and the visible bias helps RBM to reconstruct the input during a backward pass. The reconstructed input is always different from the actual input as there are no connections among the visible units and therefore, no way of transferring information among themselves.
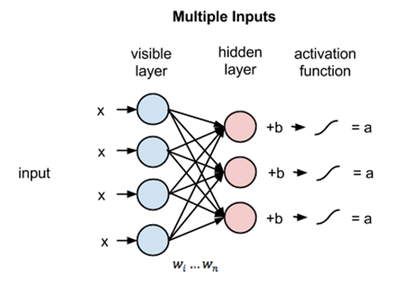
Step 1
The above image shows the first step in training an RBM with multiple inputs. The inputs are multiplied by the weights and then added to the bias. The result is then passed through a sigmoid activation function and the output determines if the hidden state gets activated or not. Weights will be a matrix with the number of input nodes as the number of rows and the number of hidden nodes as the number of columns. The first hidden node will receive the vector multiplication of the inputs multiplied by the first column of weights before the corresponding bias term is added to it.
Here is the formula of the Sigmoid function shown in the picture:
So the equation that we get in this step would be,
where h(1) and v(0) are the corresponding vectors (column matrices) for the hidden and the visible layers with the superscript as the iteration v(0) means the input that we provide to the network) and a is the hidden layer bias vector.
(Note that we are dealing with vectors and matrices here and not one-dimensional values.)
Now this image shows the reverse phase or the reconstruction phase. It is similar to the first pass but in the opposite direction. The equation comes out to be:
where v(1) and h(1) are the corresponding vectors (column matrices) for the visible and the hidden layers with the superscript as the iteration and b is the visible layer bias vector.
Now, the difference v(0)−v(1) can be considered as the reconstruction error that we need to reduce in subsequent steps of the training process. So the weights are adjusted in each iteration so as to minimize this error and this is what the learning process essentially is.
In the forward pass, we are calculating the probability of output h(1) given the input v(0) and the weights W denoted by:
And in the backward pass, while reconstructing the input, we are calculating the probability of output v(1) given the input h(1) and the weights W denoted by:
The weights used in both the forward and the backward pass are the same. Together, these two conditional probabilities lead us to the joint distribution of inputs and the activations:
Reconstruction is different from regression or classification in that it estimates the probability distribution of the original input instead of associating a continuous/discrete value to an input example. This means it is trying to guess multiple values at the same time. This is known as generative learning as opposed to discriminative learning that happens in a classification problem (mapping input to labels).
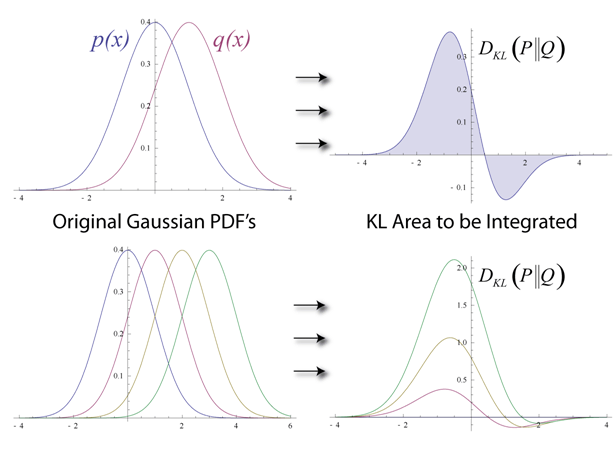
Let us try to see how the algorithm reduces loss or simply put, how it reduces the error at each step. Assume that we have two normal distributions, one from the input data (denoted by p(x)) and one from the reconstructed input approximation (denoted by q(x)). The difference between these two distributions is our error in the graphical sense and our goal is to minimize it, i.e., bring the graphs as close as possible. This idea is represented by a term called the Kullback–Leibler divergence.
KL-divergence measures the non-overlapping areas under the two graphs and the RBM’s optimization algorithm tries to minimize this difference by changing the weights so that the reconstruction closely resembles the input. The graphs on the right-hand side show the integration of the difference in the areas of the curves on the left.
This gives us intuition about our error term. Now, to see how actually this is done for RBMs, we will have to dive into how the loss is being computed. All common training algorithms for RBMs approximate the log-likelihood gradient given some data and perform gradient ascent on these approximations.
Contrastive Divergence
Here is the pseudo-code for the CD algorithm:
CD Algorithm pseudo code
Applications: * Pattern recognition : RBM is used for feature extraction in pattern recognition problems where the challenge is to understand the hand written text or a random pattern. * Recommendation Engines : RBM is widely used for collaborating filtering techniques where it is used to predict what should be recommended to the end user so that the user enjoys using a particular application or platform. For example : Movie Recommendation, Book Recommendation * Radar Target Recognition : Here, RBM is used to detect intra pulse in Radar systems which have very low SNR and high noise.
Source: wikipedia (https://en.wikipedia.org/wiki/Restricted_Boltzmann_machine)
I am so pleased to share the news that I was one of the speakers at the ATAL Online Faculty Development Program, a 5-days course conducted by Chandigarh University and was Organized By Department of Electronics & Communication Engineering, Chandigarh University. The programme was accepted and approved by AICTE Training and Learning (ATAL) Academy cell.
The sessions were conducted by the team of eminent academicians and industry experts possessing in-depth knowledge in the area of Internet of Everything. Topis covered were:
Introduction to embedded systems, IOT and IOE
Internet of Everything v Internet of things
IOT Network and Protocols
IOT System architecture -Design and Development
IOT Programming and Simulator
Security and Privacies issues in IOT
Cloud deployment and its application in IOT
IOT/IOE in Healthcare applications
AI Powered IOT/IOE
Building a sample IOT application
I spoke on Day 5 Session 1. My topic was “IoT for Retail Management”.
I spoke about various ways Retail Industry is using the IoT to manage their store, customer experience, employee management and supply chain. Other speakers at the event were:
In my next blog, I will write about the content I presented at the event. Stay tuned!
Other speakers at the event were:
In my next blog, I will write about the content I presented at the event. Stay tuned!
Another article talking about the basic concept of machine learning and data science.
As the world has entered the time period of big data, so did the demand for data containers. Until 2010, it was the main threat and consideration for the corporate businesses. The primary focus was on developing a framework and data storage systems. When is it going to happen? The secret sauce here is data science. Data Science can make all of the ideas that you see in Hollywood sci-fi movies a reality. The destiny of Artificial Intelligence is Data Science. As a result, it is essential to recognize what Data Science is and how it might benefit your company?
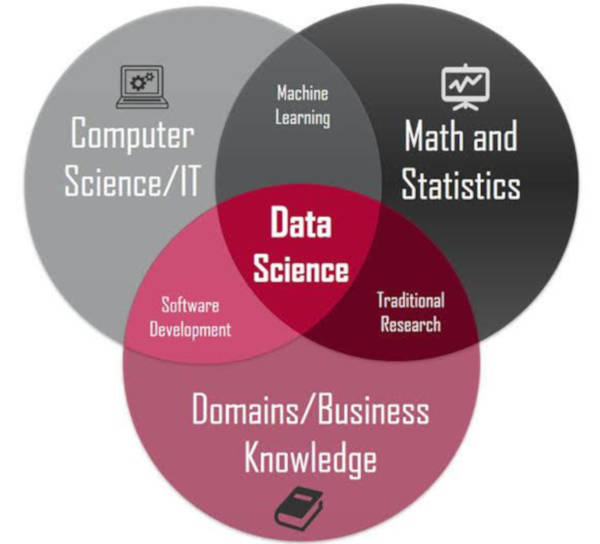
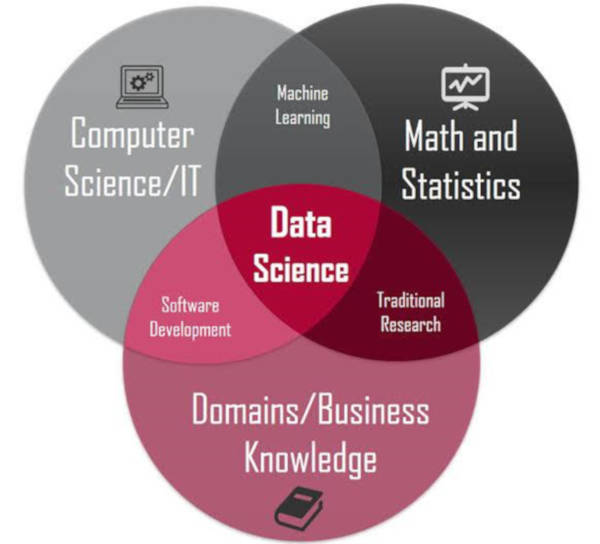
What is Data Science? Data Science is a collection of tools, techniques, and deep learning fundamentals that aim to uncover hidden styles in original data. But how does this differ from what statistical methods have done for years? As shown in the preceding image, a Data Analyst typically explains what is happening on by tracing the data’s handling background. A Data Analyst, on the other hand, not only performs exploratory analysis to glean insights from it, but also employs a variety of advanced machine learning techniques to predict the occurrence of a specific event in the future. A Data Scientist will examine the data from a variety of perspectives, including some that were previously unknown.
Do you need a data science certificate? A certification on your resume is unlikely to help you land a job. Employers are interested in the skills you possess. A registration, by itself, tells an employer nothing about your abilities. It simply informs them that you researched a subject. Certifications, on the other hand, can be extremely valuable if they effectively teach you the skills you require. Certification programmes and platforms can still be a great investment, but please remember that their value is in the skills they can instruct you. Employers will look at your skills, project portfolio, and transferable skills when they review your resume. A certificate is unlikely to sway their decision, so focus on developing the necessary skills and creating exciting projects.
Why is data science important? Data science is essential in almost all aspects of business and techniques. For example, it offers data about consumers that enables businesses to create more effective marketing plans and targeted marketing in order to increase product sales. It aids in the management of financial risks, the detection of fraudulent purchases, and the prevention of equipment failure in production facilities and other industrial sites. It aids in the prevention of cyber-attacks and other security threats in IT systems. Data science initiatives can improve operational management in the supply chains, product inventory levels, distribution channels, and customer service. On a more basic level, they point the way toward greater efficiency and lower costs. Data science also allows enterprises to develop strategic initiatives based on an in-depth analysis of customer behavior, market trends, and competition. Without it, business owners risk missing out on possibilities and making bad choices.
Challenges in data science: Due to the obvious advanced essence of the data analysis involved, data science is especially challenging. The massive amounts of data that are typically analyzed contribute to the complexity and lengthen the time it would take to execute tasks. Furthermore, data scientists regularly work with pools of big data that may encompass a mix of structured, unstructured, and semi-structured data, confounding the analytics platform even further. Removing bias in data sets and advanced analytics is one of the most difficult challenges. This includes both problems with the original data and problems that data scientists unconsciously build into algorithms and prescriptive models. If such biases are not identified, they can skew analytics results, resulting in flawed findings and poor business decisions. Worse, they can have a negative impact on specific groups of people, as in the particular instance of ethnic partiality in AI technologies.
Why businesses need Data Science? We’ve progressed from working in small frames of structured data to huge mining areas of unorganized and semi-structured info coming in from a variety of sources. When it tends to come to having to process this huge pool of unstructured information, conventional Business Intelligence tools fall short. As a result, Data Science includes more sophisticated tools for working with large volumes of data from various sources such as economic logs, multimedia content, advertising forms, detectors and tools, and text files.
What does a data scientist really do? Algorithms are created and used by data scientists to analyses data. In general, this process entails using and developing machine learning tools and personalized data goods to interest of business and clients in interpreting data in a useful manner. They also aid in the breakdown of data-driven reports in order to gain a better understanding of the clients. Overall, data scientists are involved in every stage of data processing, from processing it to creating and maintaining facilities, testing, and analyzing it for real-world applications.
All these are more information are available in the book “Data Science and Machine Learning with Python” by Swapnil Saurav. Available on Amazon here
In continuation to our earlier discussions, and talking about basic terms first before we get into higher level of discussions, in this article I talk about what is AI from my perspective.
Artificial intelligence (AI) is a subfield of computer science concerned with the simulated world of human intelligence in machines. Another way to think about AI is as a quest to create machines that can perform specific tasks that require human intelligence. AI has the potential to free us from monotonous tasks, make quick and accurate decisions, act as a catalyst for accelerating discoveries and inventions, and even complete dangerous processes in extreme environments. There is no magic in this place. It’s a group of intelligent algorithms attempting to mimic human intellect. AI employs techniques such as machine learning and deep learning to learn from data and improve on a regular basis. And AI is more than just a subfield of computer science. Rather, it incorporates elements of statistics, mathematics, intelligent systems, neuroscience, cybernetics, psychology, philology, philosophy, economy, and other disciplines.
Different types of AI: At a very high level, artificial intelligence can be split into two broad types:
Narrow AI: Narrow AI is what we see everywhere us in computing systems. It refers to expert machines that have been taught and learned how to perform specific tasks without being pattern recognition to do so. This class of machine intellect is visible in the Siri digital assistant on the Apple iPhone’s communication – language acknowledgment, visual acuity systems on ego cars, and recommendation engines that accurate recommendations you might like predicated on what you’ve purchased in the history. These processes, unlike humans, can only learn or be taught how to perform specific tasks, which is why they are referred to as narrow AI.
General AI: General AI is very unique and is the a kind of flexible intellectual ability found in people, a flexible form of intelligence smart enough to learn how to hold out massively various tasks, such as hairdressing, building spreadsheet applications, or reasoning about a wide range of topics based on its collective experience. This is the type of AI seen in films, such as HAL in 2001 or Skynet in The Terminator, but it does not exist today – and AI specialists are divided on the how shortly it would become a actuality.
How Artificial Intelligence (AI) Works? Constructing an AI system is a meticulous process that involves reverse-engineering human characteristics and abilities in a machine and then using its supercomputing prowess to outperform what we are competent of. To comprehend How Artificial Intelligence Works, one must first delve into the various subsites of Ai Technology and comprehend how those domains can be applied to various areas of business. You can also enroll in an artificial intelligence course to develop a full understanding.
What is the Purpose of Artificial Intelligence? The goal of Artificial Intelligence is to augment human ability and assist us in making complex decisions with far-reaching consequences. From a technical standpoint, that is the answer. From a philosophical standpoint, Artificial Intelligence is the ability to help human’s live more good lives free of hard labor, as well as to assist in managing the complex web of interconnected individual people, businesses, states, and nations to function in a way that benefits all of civilization. Currently, the objective of Artificial Intelligence is communicated by all the various techniques that we’ve created over the last long time – to optimize human effort and assist us in making important choices. Artificial intelligence has also been dubbed our “Final Discovery,” a conception that would create ground-breaking tools that would tremendously change how we live our lives, ideally eradicating conflict, unfairness, and human misery.
Where is Artificial Intelligence (AI) Used? AI is used in a variety of domains to provide insights into user behavior and make suggestions based on data. Google’s forecasting search algorithm, for example, used previous user data to determine what a user would type next in the search field. Netflix uses past user data to suggest what movie a user should watch next, keeping the user on the forum and increasing watch time. Facebook uses past user data to instantly suggest tags for your friends predicated on their facial characteristics in their images. AI is being used by large organizations all over the world to make the lives of end users easier. AI could be used to rapidly and conveniently complete tasks that humans find tedious, such as trying to sort through huge amounts of data and recognizing styles. It also enables machines to become cleverer in ways that would make them more convenient, easier to use, and competent of accomplishing more than ever before. This applies to our personal devices and larger industry technologies, as well as virtually everything between.
All these are more information are available in the book “Data Science and Machine Learning with Python” by Swapnil Saurav. Available on Amazon here
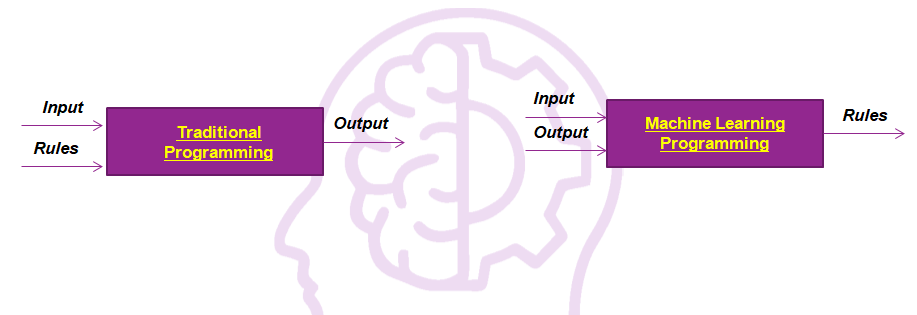
Hello again. Welcome to my blog, this is my third post. I will talk about different applications of Machine Learning as well as share code and applications in future posts. But before that, I would like to talk about basics so those you are looking to understand the concepts would find it very useful. In this post, we will see what is machine learning.
Machine learning is a method of data analysis that automates analytical model building. It is a branch of artificial intelligence based on the idea that systems can learn from data, identify patterns and make decisions with minimal human intervention.
Machine learning, at its most basic, is the method of training a computer system to make correct estimates when given data. Those forecasts could include determining whether a piece of fruit in a photograph is a banana or an apple, detecting people crossing a road in front of a self-driving car, determining whether the use of the term book in a statement refers to a printed book or a hotel reservation, determining whether an email is spam, or accurately recognizing speech to start generating subtitles for a Youtube clip.
The main difference between this and conventional computer software is that a human creator did not write the code that tells the scheme how to discern the difference between a banana and an apple. Instead, a machine-learning model has been trained to reliably distinguish between the fruits by being educated on a large amount of data, most likely a huge number of images labeled as comprising a piece of fruit.
Why Do We Need It? As the name implies, machine learning is an active process in which computers learn and analyses data fed to them in order to determine the future. There are various types of learning, such as supervised, unmonitored, semi-supervised, and so on. Machine learning is a stepping stone to artificial intelligence; it learns from algorithms based on databases and originates answers and comparisons from them. Equipment and digital conversion are inextricably linked, and machine learning is at the heart of both. Google announced its graph-based machine learning tool in 2016. It connected data clusters based on the similarities using the semi-supervised active learning. Machine learning algorithms assists industries in identifying market dynamics, possible risks, customer requirements, and business insights. Today, business analytics and mechanization are the norms, and machine learning is the foundation for achieving these goals and increasing your operational productivity.
How Machine Learning Works? Machine Learning is without a hesitation one of the most intriguing subsets of Artificial Intelligence. It performs the tasks of data studying by providing specific inputs to the machine. It is critical to recognize how Machine Learning works and, as a result, how it could be used in the long term. The Machine Learning process begins with the input of training data into the chosen algorithm. To see if the machine learning model is working properly, incoming data information is passed into it. The forecasting and the results are then cross-checked. If the prediction and results do not match, the methodology is re-trained several times until the data scientist obtains the desired outcome.
Why is Machine Learning Important? Recognize the ego Google car, cyber fraud prevention, and online suggestion engines from Facebook, Netflix, and Amazon to gain a better understanding of Machine Learning’s applications. All of these things can be enabled by machines by filtering valuable information and cobbling it all together premised on the patterns to produce reliable data.
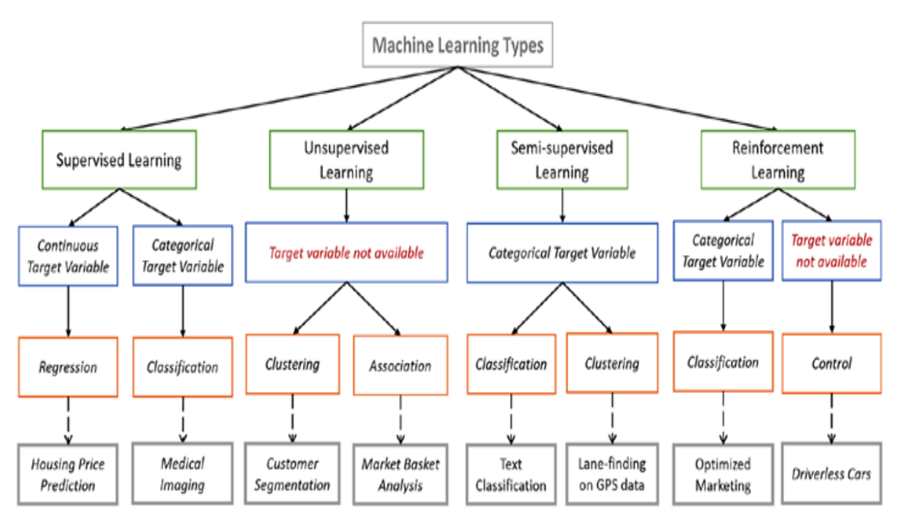
Different Types of Machine Learning
Supervised Learning: The machine learning model in supervised learning is recognized or labeled data. Because the data is known, the knowledge is monitored, i.e. directed toward successful implementation. The input data is processed by the Machine Learning algorithm, which is then used to train the model. Once the model has been trained on existing data, you can feed unknown data into it to get a reasonable response. In this particular instance, the model attempts to determine whether the data is an apple or another type of fruit. Again when the model has been properly trained, it will recognize the data as an apple and respond accordingly.
Unsupervised Learning: The training set in unsupervised classification is unidentified and unidentified, implying that no one has previously examined the data. The contribution cannot be steered to the automated system without the component of known data, which is where the term “unsupervised” comes from. This information is fed into the Machine Learning algorithm, which is then used to train a model. The model attempts to find a pattern and provide the expected reaction. In this case, it frequently appears that the algorithm is attempting to break code in the same way that the Enigma machine did, but without the human brain involved directly, but rather a machine. In this case, the unknown data consists of apples and pears that resemble one another. The trained model attempts to group them all so that you get the same things in similar organizations.
Reinforcement Learning: In this case, the algorithm, like in conventional kinds of data assessment, uncovers data through trial and error and then makes the decision which action leads to higher rewards. Learning algorithm is made up of three major elements: the agent, the surroundings, and the behavior. The student or judgment is the agent, the environment encompasses everything with which the agent comes into contact, and the activities are what the representative does. Reinforcement learners learn when the agent selects actions that maximize the immediate value over a specified time period. This is simplest to accomplish when the agent works within a solid policy structure.
Machine Learning types and different algorithms
I am leaving you with this picture, we will talk about these in coming posts.
For detailed discussion, you can refer my book on Machine Learning (using Python examples): Buy on Amazon
(first appeared on Lambda and Sigma post – read here)