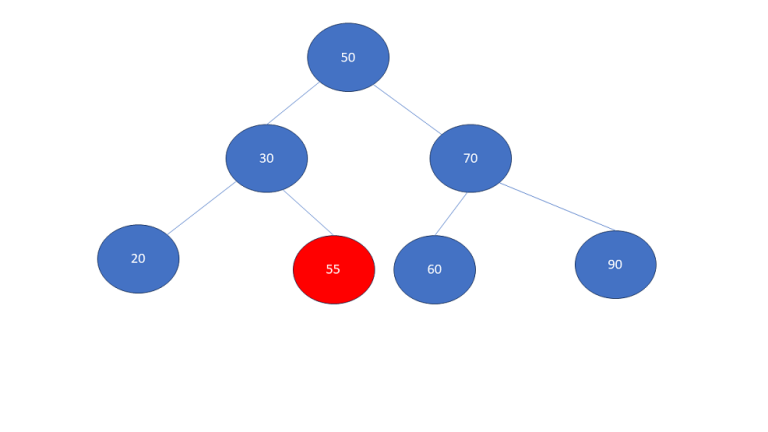
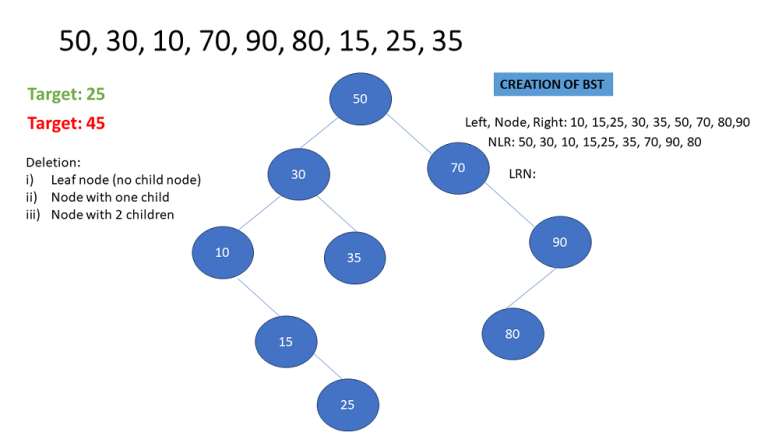
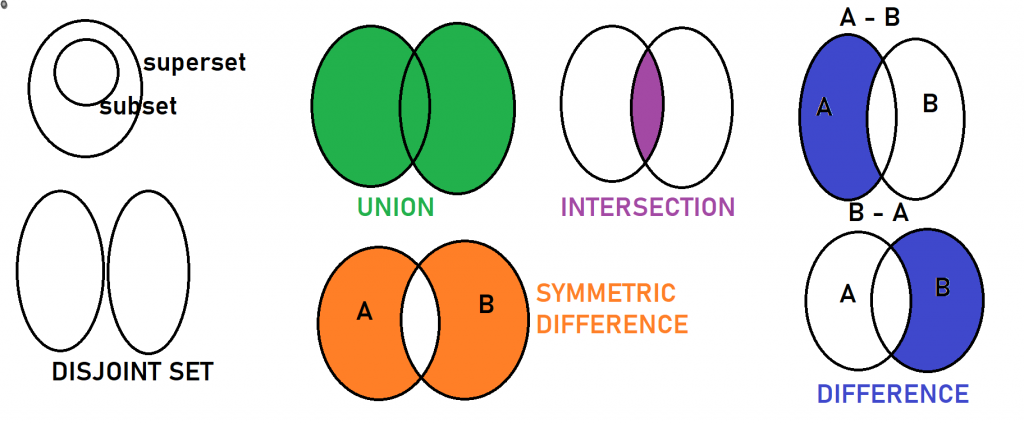
Object Oriented Programming – Properties using Python
”’
ENCAPSULATION:
1. Giving required access to the user:
a. public access: public members can be called by any class from any where
b. protected access (_member): this behaves like public
c. private access (__member): This is visible only within the class (NOT Outside the class)
”’
class Patient:
total = 0
def getinfo(self, name,age):
self.name = name
self.age = age
self.__yob = 2023-age # private member
print(“Name is: “,self.name)
print(“Age is: “,self.age)
print(“You were born in the year”,self.__yob)
self._yearofbirth()
def _yearofbirth(self): # protected member
print(“Method: You were born in the year”,2023 –self.age)
class OutPatient(Patient):
def op_data(self,dept,hospital):
self.dept = dept
self.hospital = hospital
print(“Department: “,self.dept)
print(“Hosipital: “,self.hospital)
def fp_data2(self,a,b):
print(“OutPatient: Patient is from Dubai!”)
class ForeignPatient(OutPatient):
def fp_data(self):
print(“Patient is from Dubai!”)
def fp_data(self,a):
print(“Patient is from Dubai!”)
def fp_data3(self,a,b):
print(“ForeignPatient: Patient is from Dubai!”)
p1 = Patient()
p1.getinfo(“Sachin”,51)
print(p1.name)
#print(p1.__yob)
p1._yearofbirth()
# protected members, by definition it exists in Python but
# practically its like public members
op1 = OutPatient()
op1.op_data(“General Checkup”,“Apollo”)
op1.getinfo(“Virat”,35)
fp1 = ForeignPatient()
fp1.getinfo(“Warner”, 38)
#fp1.fp_data() – this would work in Java & C++ but not in Python
fp1.fp_data2(3,5)
#fp1.fp_data(7) – this would work in Java & C++ but not in Python
ENCAPSULATION:
1. Giving required access to the user:
a. public access: public members can be called by any class from any where
b. protected access (_member): this behaves like public
c. private access (__member): This is visible only within the class (NOT Outside the class)
”’
class Patient:
total = 0
def getinfo(self, name,age):
self.name = name
self.age = age
self.__yob = 2023-age # private member
print(“Name is: “,self.name)
print(“Age is: “,self.age)
print(“You were born in the year”,self.__yob)
self._yearofbirth()
def _yearofbirth(self): # protected member
print(“Method: You were born in the year”,2023 –self.age)
class OutPatient(Patient):
def op_data(self,dept,hospital):
self.dept = dept
self.hospital = hospital
print(“Department: “,self.dept)
print(“Hosipital: “,self.hospital)
def fp_data2(self,a,b):
print(“OutPatient: Patient is from Dubai!”)
class ForeignPatient(OutPatient):
def fp_data(self):
print(“Patient is from Dubai!”)
def fp_data(self,a):
print(“Patient is from Dubai!”)
def fp_data3(self,a,b):
print(“ForeignPatient: Patient is from Dubai!”)
p1 = Patient()
p1.getinfo(“Sachin”,51)
print(p1.name)
#print(p1.__yob)
p1._yearofbirth()
# protected members, by definition it exists in Python but
# practically its like public members
op1 = OutPatient()
op1.op_data(“General Checkup”,“Apollo”)
op1.getinfo(“Virat”,35)
fp1 = ForeignPatient()
fp1.getinfo(“Warner”, 38)
#fp1.fp_data() – this would work in Java & C++ but not in Python
fp1.fp_data2(3,5)
#fp1.fp_data(7) – this would work in Java & C++ but not in Python